BERT 论文笔记
BERT 论文笔记
论文主要信息
- 标题:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- 作者:Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova
- 机构:Google AI Language
- 来源:NAACL-HLT 2019(Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies)
- 代码:https://github.com/google-research/bert
摘要 Abstract
本文介绍一个新的语言表示模型BERT(Bidirectional Encoder Representations from Transformers)。叫BERT和它的想法主要来自于另一份工作ELMo(芝麻街中的角色)很有关系。主要引用了ELMo和GPT两篇文章,BERT训练深的双向的表示,使用的是没有标号的数据,联合左右的上下文信息。因为我们的设计导致训练好的BERT,只需要加一个额外的输出层,就可以在很多的NLP任务上得到不错的结果,包括问答、语言推理等,而且不需要对任务做特别的架构上的改动。相比GPT的利用单向,左边的上下文信息预测未来,BERT使用的是左右侧双向的信息。相比ELMo使用的RNN的架构,BERT使用的是Transformer,所以当ELMo使用到较下游的任务的时候需要对架构进行调整,而BERT的地方相对比较简单,只需要改最上层就行(和GPT比较一样)。
BERT在概念上更加简单,而且在实验上更加好,在11个NLP任务上得到了更好的结果,包括GLUE、MultiNLI、SQuADv1.1、SQuADv2.0等(包括详细的精度比较)。
1. 引言 Introduction
在语言模型里,预训练可以用来提升很多自然语言的任务。比如词嵌入、GPT等。这些自然语言任务里包括两类,第一类叫句子层面的任务,建模句子之间的关系,比如对句子情绪的识别、分析两个句子之间的关系;第二类任务是词语言层面的任务,比如实体命名的识别和问答,这类任务需要输出一些细粒度的词元层面的输出。
在使用预训练模型做特征表示的时候,一般有两类策略,第一种是基于特征的,第二种是基于微调的。第一种基于特征的代表作是ELMo,它对每一个下游的任务,构造一个和这个任务相关的神经网络(RNN),在预训练好这些表示后,作为一个额外的特征一起输入进这个模型里,希望这些特征有了比较好的表示,让模型训练比较容易。第二种基于微调的例子是GPT,把预训练好的模型放在下游后不需要改开头的,只需要在下游的任务上微调一下。这两个途径都是在使用一个相同的目标函数,使用一个单向的语言模型(根据前文去预测未来的语言)。
现在这样的技术有局限性,特别是在做预训练的表示的时候(pre-trained representations),主要问题是标准的语言模型是一个单向的,导致在选架构的时候有一定的局限性,比如GPT里面使用的是一个从左到右的架构,这个东西不是很好,如果要做一个句子层面的分析的话,比如一次从左看到右和从右看到左(完整看整个句子)都是合法的,如果要做一个词元级别的任务的时候,比如问答任务的时候,也是可以看完整个句子后去选答案,而不是必须要一个一个往下走。如果我把两个方向的信息都放进来之后,应该是能提高相关任务的性能的。
在这篇论文中,提出了BERT,BERT是用来减轻之前提到过的语言模型是单向的限制。它使用的是一个带掩码(MLM, Masked Language Model)的语言模型,这个东西是受一个叫Cloze task(1953年的一篇论文)的启发。这个带掩码的语言模型每次随机的选一些词元把它们盖住,然后目标函数就是预测那些被盖住的词,类似完形填空。这样允许我们训练一个深的双向的语言模型,在带掩码的模型之外,还有另一个任务预测下一个句子(NSP, Next Sentence Prediction),给两个句子,判断两个句子在原文中是否相邻,还是随机采样的两个句子放在一起。这样能让模型学习一些句子层面的信息。
这篇文章的贡献,作者罗列了三点:
- 展示了双向信息的重要性。GPT只用了单向,之前有的工作是把一个从左看到右的语言模型和从右看到左的语言模型简单合并在一起,有点像双向的RNN模型,把它们链接在一起。BERT在双向信息的运用上更合理一些。
- 假设有一个比较好的预训练的模型的话,就可以不用对很多特定任务做特定的模型的改动了。BERT是在一系列NLP任务上的第一个基于微调的模型,这些任务包括句子层面、词元层面的任务上,都取得了最好的成绩。
- 代码和模型全部放在这里,大家可以随便用。
6. 结论 Conclusion
最近的一些实验表明使用非监督的预训练是非常好的,这样使得资源不多的任务,比如训练样本比较少的任务也能享受深度神经网络。作者主要的工序就是把前人的结果拓展到一个深的双向的架构上面,使得同样的一个预训练模型能够处理大量的NLP的任务。主要是把ELMo使用双向的想法和GPT使用Transformer的东西合起来,就成了BERT,具体的改动是在做语言模型的时候,从预测未来变成了完形填空。
2. 相关工作 Related Work
2.1. 非监督的基于特征的工作 Unsupervised Feature-based Approaches
主要是之前提到的ELMo,介绍了一些。
2.2. 非监督的基于微调的工作 Unsupervised Fine-tuning Approaches
代表作是GPT,和一些相关的工作。
2.3. 有监督的数据上做迁移学习 Transfer Learning from Supervised Data
在NLP中有监督的数据包括了自然语言的一些推理和机器翻译,在这些有标号的数据集上训练好后在别的任务上使用。类比CV中这一块使用是很多的,比如大家在ImageNet上训练好模型,再去别的地方使用,但是在NLP这块似乎不是那么的理想。这两个任务(推理和机器翻译)可能和别的任务差别还是挺大的,也可能是数据规模是远远不够的。BERT以及之后的一些研究证明了在NLP上面使用没有编号的大量的数据集训练成果比有标号的小的数据集上效果更好。
3. BERT
在这一章中主要讲BERT的实现的细节。第一个叫预训练(pre-training)和微调(fine-tuning)。在预训练的时候模型是在没有标号的数据集上训练的,在微调的时候就是在下游任务的时候基于预训练好的模型在有标号的数据集上继续训练。每一个下游任务都会有一个新的BERT模型,虽然他们用的都是一样的预训练模型进行参数的初始化,但是对每一个下游任务,都会根据自己的数据训练自己的模型,在图1里面进行了展示。
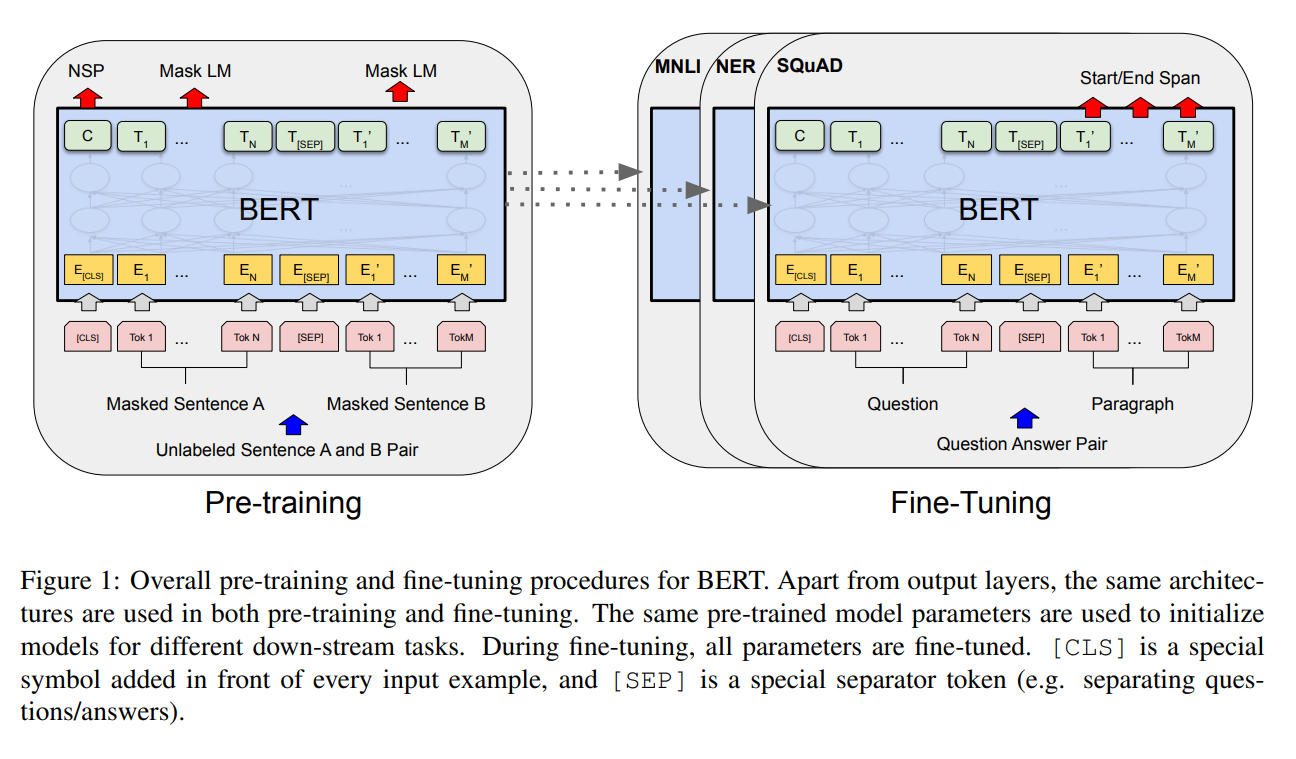
模型架构 Model Architecture
BERT模型架构是一个多层的双向的Transformer的编码器,而且是直接基于原始的论文和原始的代码,没有做什么改动。(BERT’s model architecture is a multi-layer bidirectional Transformer encoder based on the original implementation described in Vaswani et al. (2017) and released in the tensor2tensor library.)
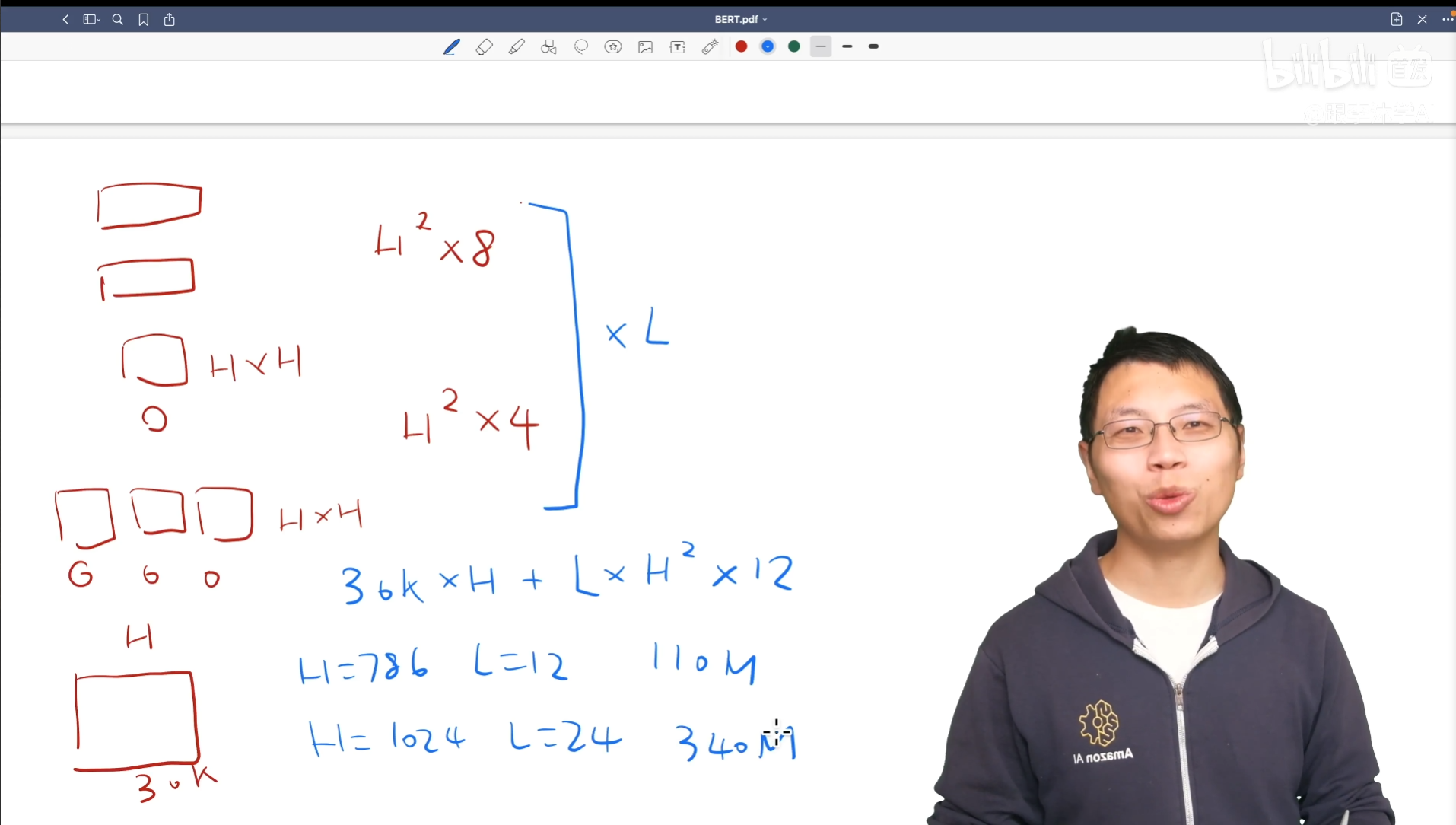
在这篇文章的工作中,调了3个参数,第一个是Transformer块的个数、层数$L$,第二个是隐藏层的宽度大小$H$,第三个是在自注意力机制里多头的头的个数$A$。作者有两个模型$BERT_{base}(L=12,H=768,A=12)$,总共学习的参数是$110M$,和$BERT_{large}(L=24,H=1024,A=16)$,总共学习的参数是$340M$。
BERTbase是选取了和GPT模型的参数数量差不多的,是用于比较的目的。BERTlarge就是用于刷榜的。
如何通过超参数的大小计算训练的参数个数,回顾Transformer的架构
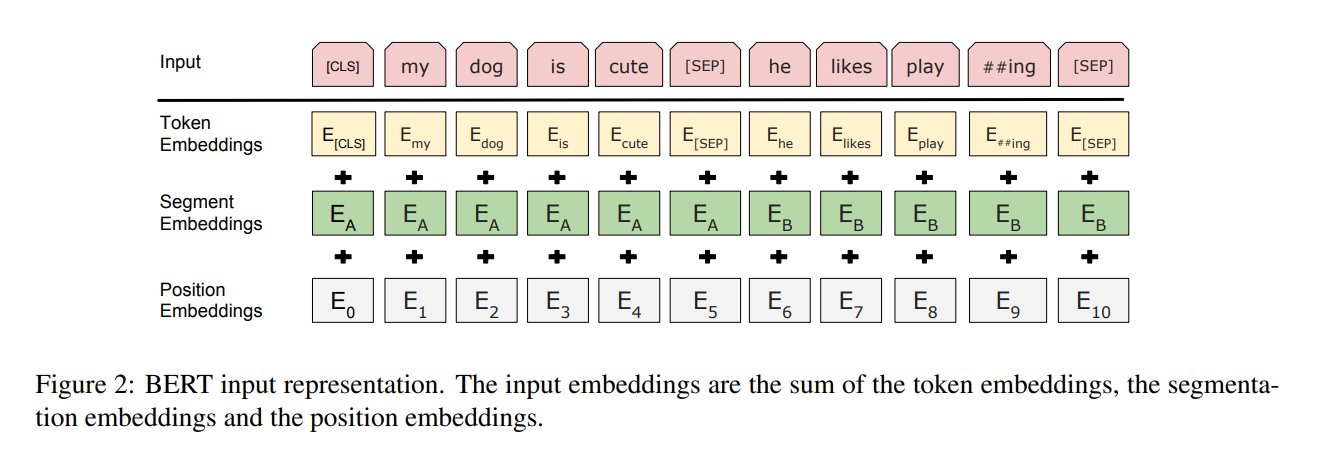
输入输出的表示 Input/Output Representations
为了让BERT能处理各种下游任务,输入的表示既可以是一个句子,也可以是一个句子对。一个句子的意思是一段连续的文字,输入是一定的文字序列。
用的切词的方法是WordPiece,如果按照空格切词的话,因为数据量很大,所以可能导致词典的大小在百万级别。如果是这样的话,之前计算出的参数数量可能会导致训练后的参数整个都在嵌入层上。WordPiece的想法是如果一个词整体出现的概率不大,那么把它切开看它的子序列,如果某个子序列出现的概率比较大的话,那么很可能是个词根,保留这个子序列就行了,这样可以把一个相对来说比较长的词切成比较小的词根。所以用一个大小大概是30000的词典就可以表示整个文本了。
输入的表示有两点:第一,序列的开始永远是一个特殊的记号[CLS],这个词的作用是BERT希望它的输出是整个序列的一个句子层面的信息。因为BERT使用的是Transformer的编码器,所以放在开头也能看到整个句子的信息。第二,两个句子合在一起,但是要做句子层面的分类,所以需要把两个句子区分开来,有两个办法来区分,第一个是在每个句子后面放一个特殊的词[SEP],第二个是学一个特殊的嵌入层来表示这个句子是第一个句子还是第二个句子,在图1里有展示它长什么样子。
对于一个词元,它进入BERT的向量表示是这个词本身的一个Embedding加上在哪个句子和在哪个位置的Embedding,在图2里有展示出来BERT是如何从一个词元的序列得到一个向量的序列,这个向量的序列会进入Transformer块。
3.1. 预训练的BERT Pre-training BERT
预训练主要关注目标函数和数据是什么?
Task#1 Masked LM (MLM)
主要先介绍了带掩码的语言模型是什么,为什么双向的信息更好。对于一个输入的词元序列,如果一个词元是由WordPiece生成的话,有15%的概率会生成一个掩码,但是对于特殊的标记符词元,不会进行替换。比如输入的词元长度是1000的话,那么就要预测150个词。
这样也有一定的问题,当做掩码的时候,会把一定的词替换成[MASK],那么在训练的时候,会看到15%的词元会对应成这个[MASK],但是在微调的时候,其实是没有这个词元的,导致在预训练的时候和微调的时候看到的数据会不一样,这样会带来一定的问题。一个解决方法是,对于这15%的被选中的掩码的词,有80%的概率是真的替换成[MASK],还有10%的概率是替换成一个随机的词元,还有10%的概率是什么都不干,但是用它来做预测。这个比例来自于有一个ablation study,跑了实验后发现这个东西还不错。

Task#2 Next Sentence Prediction (NSP)
在QA和在推理里,都是一个句子对,所以能让BERT学习一些句子层面的信息是不错的。具体来说,输入序列里有两个句子,a和b,有50%的概率是b在原文中就在a之后,有50%的概率是b就是随机选取的一个例子。在Section 5.1中有一些结果的比较,加入这个目标函数之后,能极大地提高QA和在语言推理的效果。

Pre-training data
用了两个数据集,第一个是BooksCorpus(800M words),第二个是English Wikipedia(2,500M words)。我们应该用文本层面的数据集(一篇篇的文章),这是因为Transformer确实能处理整个文章层面的信息,比散乱的句子要好。
3.2. 微调的BERT Fine-tuning BERT
BERT和一些基于编码器解码器的架构有什么不同。因为作者把整个句子对都放进去了,所以self attention能够在两端之间相互看,但是在编码器-解码器的架构里,编码器其实看不到解码器的信息,这一点在BERT里好一点。但是这一点也付出了代价,BERT不能像Transformer一样做机器翻译了。做下游任务的时候,会根据任务设计相关的输入和输出。好处是模型不怎么需要变,只需要把输入改成需要的那个句子对。如果真的有两个句子a和b的话,那么直接作为句子对输入进去就行,否则只有一个句子进行输入的话,要么是拿到第一个词元[CLS]做分类,要么是拿对应的词元去做对应的任务。不管如何,都是在最后加一个输出层,使用softmax得到一个输出的标号。
跟预训练比,微调的训练都相对便宜。所有的实验都只需要使用TPU跑一个小时就行了,使用GPU的话多跑几个小时也是可以的。具体对于每一个任务是如何构造输入输出的会在第四节进行介绍。
4. 实验 Experiments
4.1. GLUE
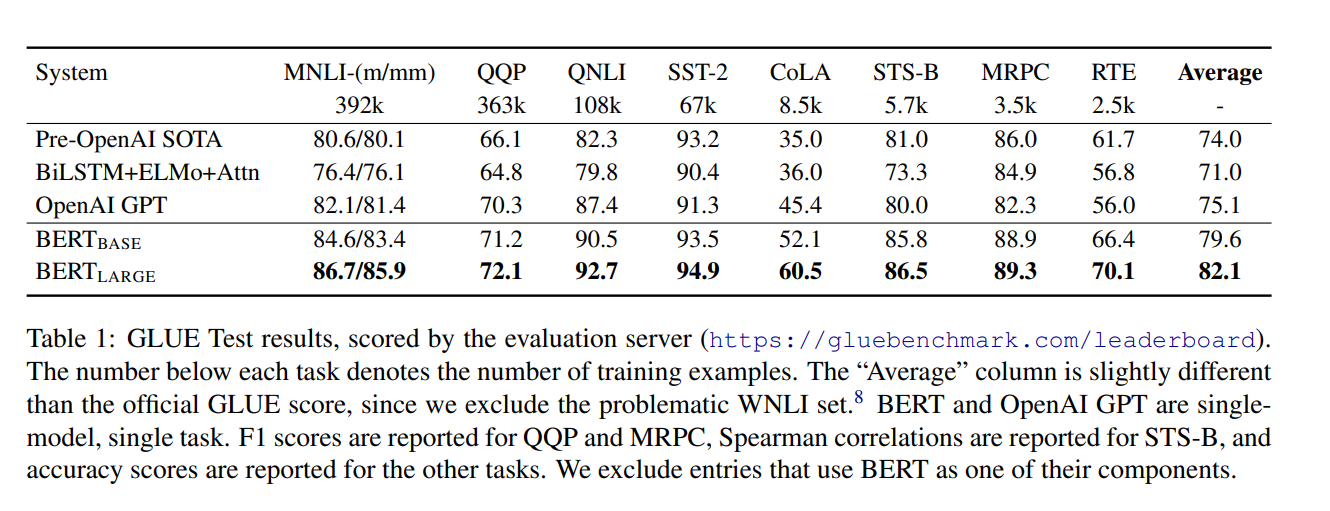
第一个是句子层面的任务GLUE。BERT是把第一个特殊词元[CLS]的最后的向量拿出来,学习一个输出层W,用softmax得到一个标号,就是一个正常的多分类问题。表1就是在GLUE所有任务上得到的一个结果展示。
4.2. SQuAD v1.1
这个是斯坦福的一个QA的数据集。在QA这个任务中,任务是给一段话,问一个问题,需要把答案找出来。答案已经在给出的那一段话里,只需要把答案对应的那一小段话找出来就可以了。任务其实就是对每个词元判断是不是答案的开头,是不是答案的结尾。BERT具体来说就是学两个向量S和E,对应的是这个词元是开头/结尾的概率。在做微调的时候使用的是3个Epoch(很小),学习率是5e-5,batch size是32。
4.3. SQuAD v2.0
QA数据集的2.0版本
4.4. SWAG
用来判断两个句子的关系,和之前的训练没有太大区别,BERT结果也是比其他的要好。
5. 消融研究 Ablation Study
5.1. Effect of Pre-training Tasks
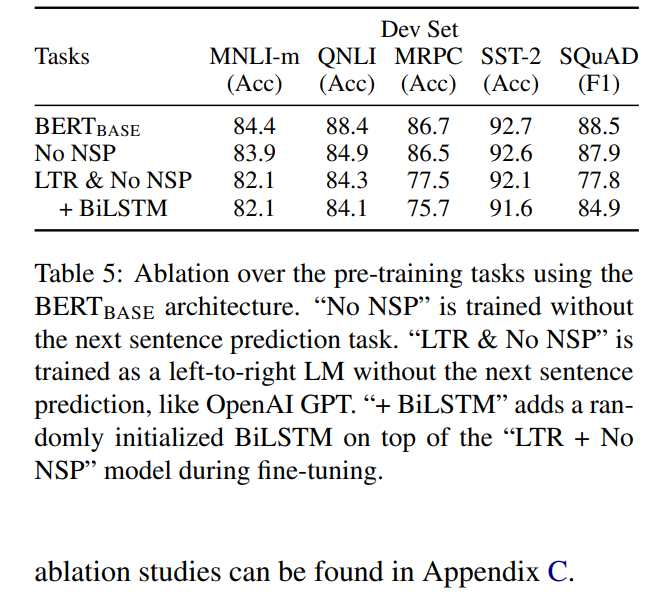
如果去掉了NSP任务、或者去掉双向的机制会如何,发现BERT的效果都会打折,可见表5。
5.2. Effect of Model Size
研究模型大小的影响。想法是和NLP其他模型是差不多的,认为当模型参数越来越大的时候,效果也会越来越好。认为这个是第一个展示了如果把模型变得特别大的时候,语言模型会有比较大的提升的工作。从现在角度来看,BERT的参数并不大,只有一个亿(GPT3的参数有一千个亿),甚至模型也在越来越大。但是在三年前,BERT是开创性的工作,能把模型推到这么大。
5.3. Feature-based Approach with BERT
假设作者不用BERT做微调的时候,而是把BERT的特征作为一个静态特征输进去会怎样。结论是效果确实没有微调那么好(用BERT的话应该在下游任务进行微调)。
读后评论
沐神:
- 从写作上感觉还行,中规中矩。在这篇文章的结论里,他认为他最大的贡献是双向性,但是其实选用双向性这个词是有待商榷的。没有怎么写选用这个方法后失去了什么,比如很难做生成类的任务、机器翻译类的任务,因为相比Transformer或者GPT的架构,只有编码器而没有解码器。
- 从现在再回去看BERT的话,看到的其实是一个完整的一个解决问题的思路。符合了大家对一个深度学习的模型的期望,作者训练了一个很大很深的模型,在一个很大的数据集上训练好。这个模型训练后能通过微调用在很多小的数据集和任务上。这个在CV中用了很多年了,在NLP中BERT展示的是一个几个亿的参数训练了几百GB的数据集,很简单很暴力效果很好。沐神的疑惑:BERT是这些工作中的一篇,更大的数据集训练更好的模型,比前面都要好,类似ELMo和GPT出来的时候也是这样。BERT的作用是被后面的结果去超越。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!
如果觉得文章内容不错,还请大力支持哦~
