GPT、GPT-2、GPT-3 论文笔记
GPT、GPT-2、GPT-3 论文笔记
论文主要信息
- 标题:
- Improving Language Understanding by Generative Pre-Training(GPT)
- Language Models are Unsupervised Multitask Learners (GPT-2)
- Language Models are Few-Shot Learners(GPT-3)
- 作者:Alec Radford, Jeff Wu, Rewon Child, D. Luan, Dario Amodei, Ilya Sutskever
- 机构:OpenAI
- 来源:Computation and Language
- 代码:https://github.com/openai/gpt-3
- 目前应用:https://gpt3demo.com/
- 生成一个以假乱真的技术博客
- 根据输入的要求生成一段HTML代码
- GitHub Copilot
- 图灵测试问答机器人等等
开始之前 GPT改进路线
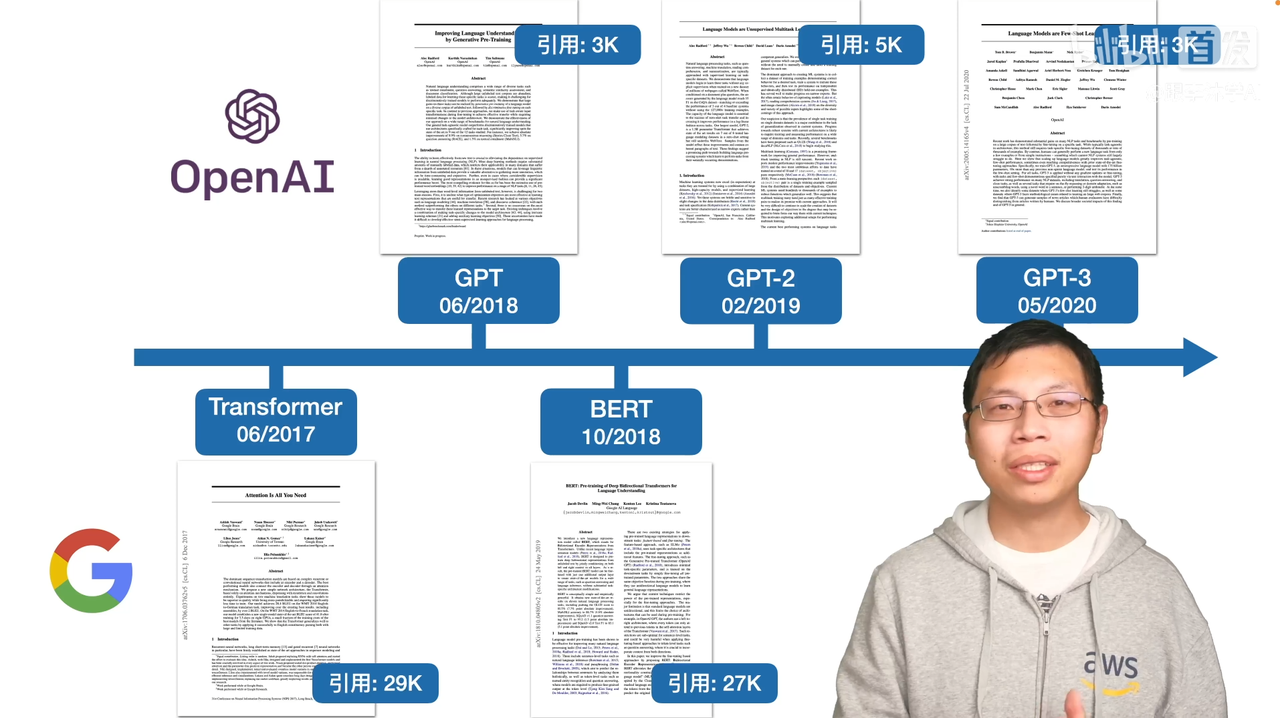
首先GPT这篇文章是在Transformer出现之后运用了Transformer的编码器,做了一个预训练模型后在做下游任务的时候做微调的模型,GPT。GPT-2是在GPT的基础上把模型做得更大,朝着zero-shot的方向迈了一大步。GPT-3是在GPT-2的基础上暴力出奇迹,数据和模型都大了100倍,然后得到了很好的效果(详见GPT-3 demo等诸多应用)。
引用率相比BERT更少,约为1/2。沐神:不是因为创新度和效果不如谷歌的BERT系列,而是因为GPT选择解决更大的问题,所以技术上实现和出效果更难一些。GPT-3这个效果规模几乎是没有别的团队能够复现的。和OpenAI想做一个强人工智能的公司背景有关系。比如Transformer就是想解决机器翻译的问题,BERT就是想把CV界的预训练好的大模型在实际任务上微调的做法搬到NLP来。
GPT | Improving Language Understanding by Generative Pre-Training
摘要 Abstract
在自然语言理解里,有很多不一样的任务。虽然有很多大量的没有标号的文本内容,但是有标号的数据是相对较少的,这使得如果我们在labeled data上训练分辨模型的话还是比较难,因为数据相对来说比较的小。作者提出的解决方法是在没有标号的数据集上训练一个预训练的语言模型,接下来再在有标号的子任务上训练一个分辨的微调模型。作者是在微调的时候构造和任务相关的输入,从而只需要很少地改变模型的架构就行了。实验结果是12个任务里有9个任务超过了已有的成绩。
1. 导言 Introduction
如何利用无标号的文本数据?在当时最成功的模型还是词嵌入模型。用没有标号的文本的时候会遇到一些困难:第一是不知道用什么样的优化目标函数,损失函数。当时有一些选择是语言模型、机器翻译或者文本的一致性,但是发现没有某一个在所有的任务上都特别好。第二个难点是如何有效地把学到的文本的表示传递到下游的子任务上。因为NLP里的子任务差别很大,没有统一的方法能一致地迁移到子任务上。
GPT这篇文章提出了一个在没有标号的文本上进行的一个半监督(semi-supervised)的方法,训练出一个预训练模型后再在下游任务上微调。后面的研究工作基于BERT和GPT的,其实被叫做自监督模型(self supervised learning)而不是半监督学习。
首先第一个技术要点是,作者用到的模型是基于Transformer的架构,原因是:跟RNN这类模型相比,Transformer在迁移学习的时候学到的feature更加稳健一些。可能是因为Transformer里面有更结构化的记忆,使得能处理更长的文本信息,从而能抽取出来更好的句子层面和段落层面的语义信息。第二个技术点是在做迁移的时候用的是任务相关的输入表示,在后文有展示。
2. 相关工作 Related Work
NLP里的半监督学习是怎样的,无监督的预训练模型是怎样的,训练的时候使用多个目标函数会怎样(Auxiliary training objectives)。分别对应的是大的GPT模型在没有标号的数据上训练出来是如何的,以及怎么样在子任务上运用有标号的数据上进行微调,以及在子任务微调的时候作者使用了两个训练的目标函数。
3. 模型框架 Framework
3.1. 无监督的预训练 Unsupervised pre-training
假设输入的一个无标号的句子信息是$U=\lbrace u_1, …, u_n\rbrace$,作者使用了一个标准的语言模型目标去最大化下面这个似然函数:
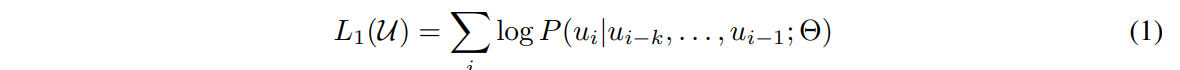
语言模型就是预测第$i$个词出现的概率。具体到公式中就是给定模型,用一个长度为$k$的上下文窗口,每次拿$k$个连续的词,预测这些连续的词后面的那个词是谁。这个$L_1$是指第一个目标函数,因为取了log所以损失函数是相加。此处$\Theta$是模型的参数,$k$是超参数。用到的模型是Transformer的解码器。Transformer的编码器和解码器最大的不一样是,编码器对序列的第$i$个元素抽取特征的时候,能看到整个序列里所有的元素,但是对解码器而言,因为有掩码的存在,所以对第$i$个元素抽取特征的时候,只会看到当前元素和它之前的这些元素,后面的内容通过掩码使得计算注意力机制的时候贡献是0。所以对这个标准的语言模型(预测下一个词出现的概率)来讲,只能使用Transformer的解码器。下面的公式对Transformer的解码器进行了一定的解释:

GPT和BERT的区别:
BERT使用的不是标准的语言模型,而是完形填空,预测的是中间的句子,能看到前后的信息,所以能使用Transformer的编码器。主要区别在于目标函数的选取,相比BERT的完形填空,GPT选择的是预测未来这个较难的目标函数(信息较少),这也是训练和效果上GPT比BERT差一点的原因。但反过来如果模型是通过这样预测未来的方式训练出来并且能得到很好的效果,那么比BERT的完形填空训练方式得到的模型要强大很多,这也是后续GPT改进的一个重要方向,做大做强。
3.2. 有监督的微调 Supervised fine-tuning
在微调任务中,数据是有标号的。每次给一个长为$m$的句子$x^1,…,x^m$和一个标签$y$,根据句子去预测标签$y$的概率。要使得这个标准的分类的概率目标函数最大化。

在微调的时候只关心分类的精度,但如果把之前预训练的语言模型函数放进来也不错,也就是说微调的时候可以使用两个目标函数的时候训练效果是最佳的。这里的$\lambda$也是一个可以调的超参数。
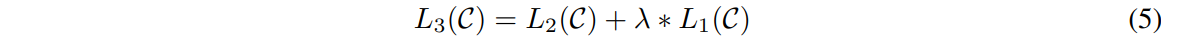
接下来要考虑的是如何把NLP的一些不同的子任务表示成这样的一个通用的输入形式。
3.3. 针对不同的子任务的输入表示 Task-specific input transformations
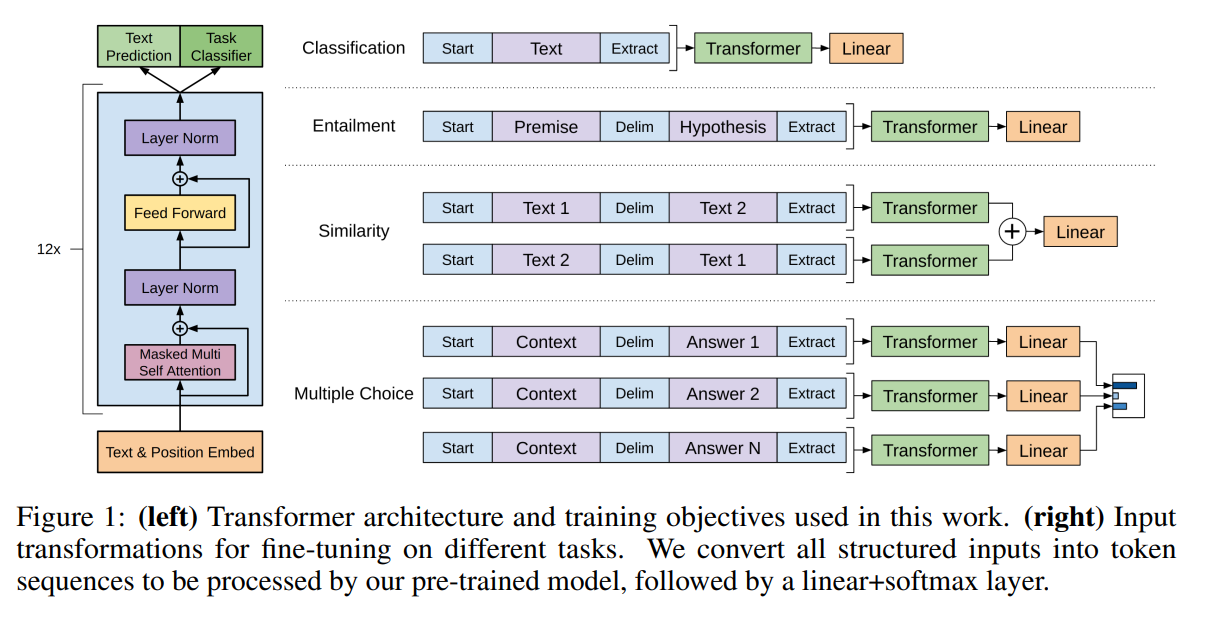
第一类是最常见的文本分类(Classification),比如对产品的评价是正面/负面。将要分类的文字在前面放一个开始(Start)的词元,后面做一个抽取(Extract)的词元,做成一个序列放进Transformer里面,把抽取的词元放到线性层(微调时新加入的)里投影到需要标号的空间。
第二类应用叫做蕴含(Entailment),给一段话,再给一个假设,判断前面这段话有没有蕴含假设提出来的东西。这个序列包含一个开始词元,分隔符(Delim)和抽取符。
第三类应用叫做相似(Similarity),给定两个文档是不是相似的,进行去重。因为相似是一个堆成的关系,如果a和b相似那么b和a相似的,但是语言模型是有先后顺序,所以这里做了两个序列,分别是ab和ba的句子顺序,两段序列分别进入模型后得到输出,再进行相加后输入到线性层得到结果。“是”或“不是”相似的一个二分类结果。
第四类应用叫做多选题(Multiple Choice),给出问题和几个答案,选出觉得正确的答案。如果有$n$个答案就构造$n$个序列,其中每个序列前面都是问题,后面就是答案。每个序列进入模型后再进入到一个线性投影层,输出的是每个答案是这个问题的答案的置信度。对每个答案计算这个标量,进行softmax后得到正确的答案置信度是多少。
不管任务是怎么变,核心的模型结构和输入表示都不会进行太大的改变。这是GPT和之前的文章一个比较大的区别,也是这篇文章的一个核心卖点。
4. 实验 Experiments
4.1 Setup
Unsupervised pre-training 在BooksCorpus这个数据集上进行训练,包含7000本没有发表的书。
Model specifications 模型包含12个解码器,每一层的维度是768。这里就是$BERT_{base}$对标的GPT的版本。
Fine-tuning details 介绍了微调的时候的超参数。
4.2 Supervised fine-tuning
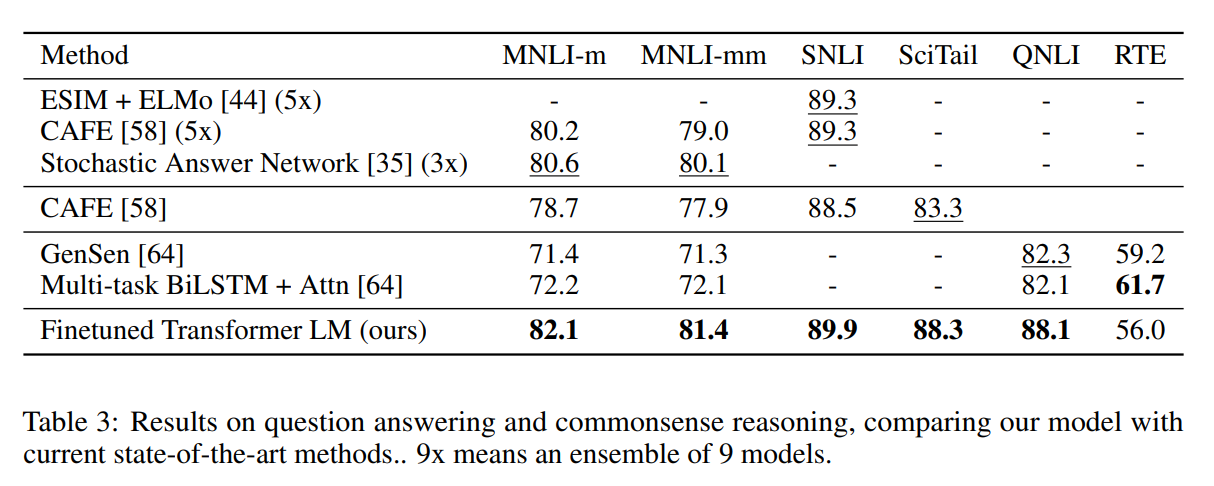
微调后对比之前的一些算法,效果都更加好。
GPT-2 | Language Models are Unsupervised Multitask Learners
摘要 Abstract
对比BERT采用的编码器,GPT系列采用的是解码器,所以如何在解码器上做到更好更强,就是GPT-2在BERT出来后要回应的问题。首先做了一个新的数据集叫WebText,有百万级别的网页文本。于是可以训练一个更大的模型(1.5B个参数,作为对比,BERT_large的参数是340M,文本变成了百万级别,模型参数3.4亿到15亿)。作者在GPT的基础上加入了zero-shot作为GPT-2的主要卖点。
1. 导言 Introduction
现在对ML systems的一个主流途径就是对一个任务收集一个数据集,然后在上面训练模型做预测。这个模型很流行是因为现在的模型的泛化性并不是很好,也就是说在一个任务上训练好的模型很难直接用到下一个任务上。多任务学习的观点是在训练一个模型的时候同时看多个数据集,可能通过增加多的损失函数来达到一个模型在多任务上都能使用(90年代末提出,00-10年比较流行的一个话题)。这个看上去很好,但是在NLP上用的不多,现在NLP主流的也是像之前GPT1和BERT那类的预训练后下游微调的模型。这样会造成两个问题:第一是对每个下游的任务还是得训练一个模型,第二个是也需要收集有标号的数据才行,这样拓展到新任务上还是有一定的成本。
GPT-2要干的事情是做语言模型的同时,在下游任务的时候要使用一个zero-shot的设定,做下有任务的时候不需要标注的信息,也不需要训练模型。
2. 方法 Approach
GPT2的模型和GPT-1差不多。GPT-1的模型在预训练的时候是没有看到微调的时候构造的开始、分隔、抽取等词符的,而是在微调的时候去认识了这些词符。但是GPT-2如果要做zero-shot的话,也就是不进行微调,如果在下游引入了模型之前没有见过的词,模型会很困惑。所以在这样的设定下,下游任务就不能引入之前模型没有见过的符号,而是要使下游任务的输入和之前的输入形式要一样,输入的形式要更像自然的语言。
比如要做机器翻译的任务,可以输入一个序列(translate to French, english text, french text),这在后面的研究中被称之为prompt(提示)。比如要做阅读理解的话,训练样例会被写成(answer the question, document, question, answer)。之后作者也花了较长笔墨解释为什么这样做是可行的,假如模型是足够强的话,也有前人的相关工作提到了这一点。
2.1. 训练数据集 Training Dataset
前人用的是Wikipedia,或者是书,作者需要使用更大的数据集才行。作者提到一个可行的方法是一个叫做Common Crawl的项目,一群人写了一个爬虫,不断地去抓取网页,把抓取的网页放在aws的s3上面,供大家免费的下载(tb级别的数量级)。作者说这个数据集不好用,因为信噪比比较低,抓取到的网页里有大量比较垃圾的网页,如果要清理它需要花很长的时间。所以他使用了大家过滤好的网页,Reddit上至少有3个karma的帖子,最后得到了4500个链接,抽取了里面的文本信息,最后这个数据集里有大概800万个文本,40GB的文字。
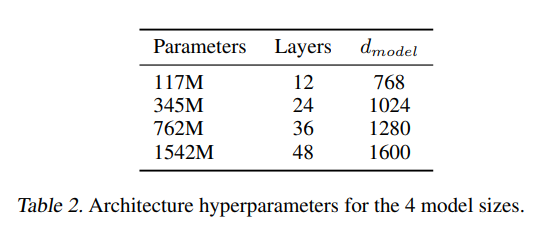
作者一共设计了4个大小不同的模型。
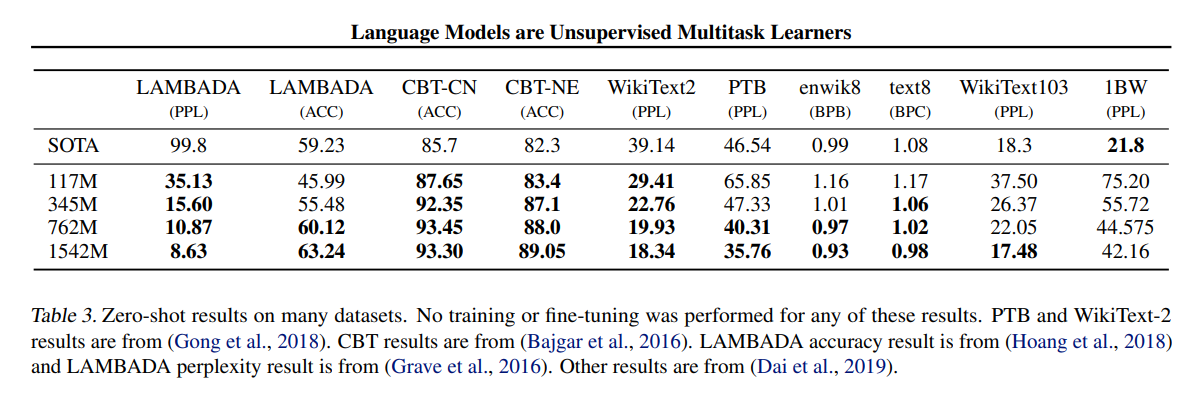
这张图表明了4个模型在不同的任务上取得的性能表现。在一些任务上做得还不错,别的任务上有一点点意思。(委婉说不太好)但是注意到随着模型变大,性能也是在上升的。

3. 实验 Experiments
主要是和别的做zero-shot的SOTA方法进行比较,和BERT那一类不太一样。
GPT-3 | Language Models are Few-Shot Learners
文章长度有63页。不是投稿的文章,是技术报告。
摘要 Abstract
作者训练了一个GPT-3模型,有175B个可学习的参数。和那些非稀疏(不会存在很多参数为0的模型)的模型比也是大了10倍。因为模型已经很大了,所以如果在做子任务的时候还要训练模型的话成本是很大的。所以GPT-3在作用到子任务上的时候不做任何的梯度更新或者微调。在NLP的任务上取得了很好的成绩(GPT-2的成绩挺差的)。GPT-3可以生成一些新闻文章,让人难以分辨是人写出来的还是生成的。
1. 导言 Introduction
最近NLP里大家都使用预训练的模型再微调。这是存在一定问题的,对每个子任务需要一个和任务相关的数据集和一个任务相关的微调。具体列举了三个问题:第一是大的数据集标注困难,第二是一个样本没有出现在数据分布里的时候,泛化性不一定比小模型微调后好(可能是过拟合预训练的训练数据),第三是人类不需要很大的数据集来做一个任务,可能通过几个例子就会掌握一个应用(few-shot)。
作者提出的解决方案是few-shot。作者取名叫meta-learning(训练了一个很大的模型,泛化性不错) / in-context learning(做下游任务即使告诉了训练样本,也不更新权重),强调的是模型权重在做下游任务的时候不做任何的更新。
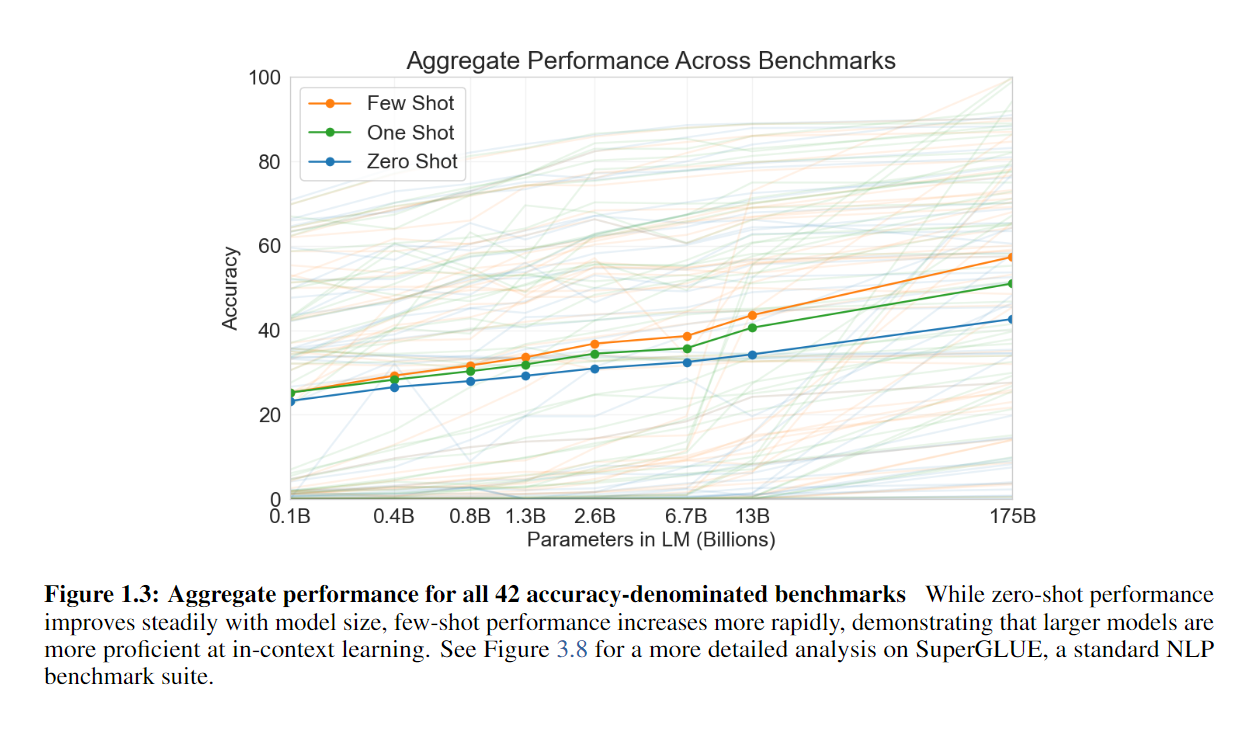
GPT-3是一个有1750亿参数的模型,评估GPT-3的3个设定是:第一是few-shot learning,给每个任务提供10-100个样本,第二是one-shot learning,可以看成few-shot learning里特别的只有一个样本的情况,第三是zero-shot learning,没有训练样本直接进行子任务。下图展示了在三个设定下模型的区别:
2. 方法 Approach

这里主要讲了微调、Few-shot、One-shot、Zero-shot具体是怎么做的。GPT-3这里就是不做梯度更新。这里Zero-shot的“=>”就是一个prompt,提示该模型去进行输出了。One-shot就是在定义好任务后给一个例子(可以看作例子作为任务的一个输入,希望模型通过注意力机制从中抽取到有用的信息),只做预测,不做训练(不更新梯度),也就是上下文学习指的事情。Few-shot就是给多个例子。
2.1. 模型架构 Model and Architectures
GPT-3的模型和GPT-2的模型是一样的。加入了一些Sparse Transformer里的改动,设计了8个不同大小的模型。
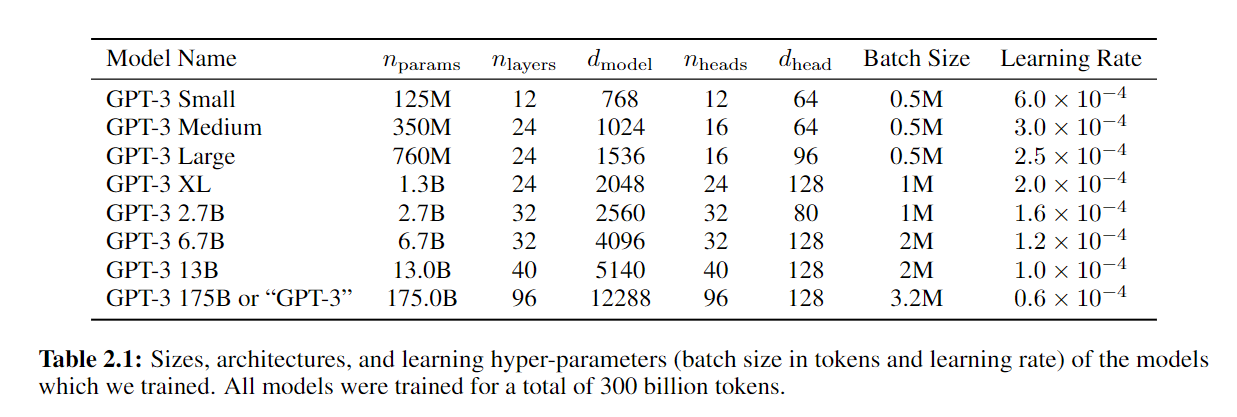
批量大小是动辄百万级别,利用了分布式机器学习在数据并行性上更高的好处。批量大小变大的时候,批量里的噪音会很大,但是在大的模型中这样噪音的影响不会很大,也就是过拟合不太经常会发生。最近也有很多工作在研究其中的原因。
2.2. 训练数据集 Training Dataset
由于GPT-3模型更大了,不得不重新考虑使用Common Crawl的数据了。在Common Crawl的数据集上基于GPT-2使用的高质量Reddit帖子的数据进行二分类,收集了更多质量偏高的文章。接下来做了一个去重的工作,具体用到的是lsh(信息检索,Information Retrieval)的算法。第三步也加了一些已知的高质量数据集,最后得到高质量的大的数据集。
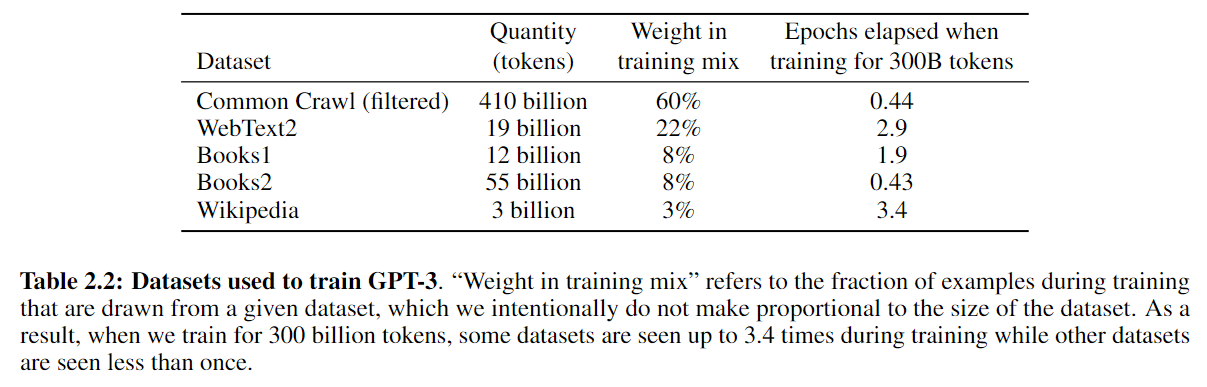
由于Common Crawl的质量还是不高,所以在batch上使用了不同的采样率,保证了更好的质量。
2.3. 训练过程 Training Process
(沐神:不“厚道”,GPT-3其实是非常难训练的。肯定有很复杂的模型分割和数据分割的过程,但是没有详细讲是怎么做这一步的)作者使用了微软的V100的DGX-1的集群,有很高的带宽。
2.4. 模型评估 Evaluation
预训练好后直接进行评估,使用了上下文学习。下游任务采样$k$个样本,prompt用的是”Answer: “或者”A: “。二分类的结果是”True”或”False”,自由的答案就是生成后进行beam search(from 机器翻译)找到一个比较好的答案。
3. 结果 Results
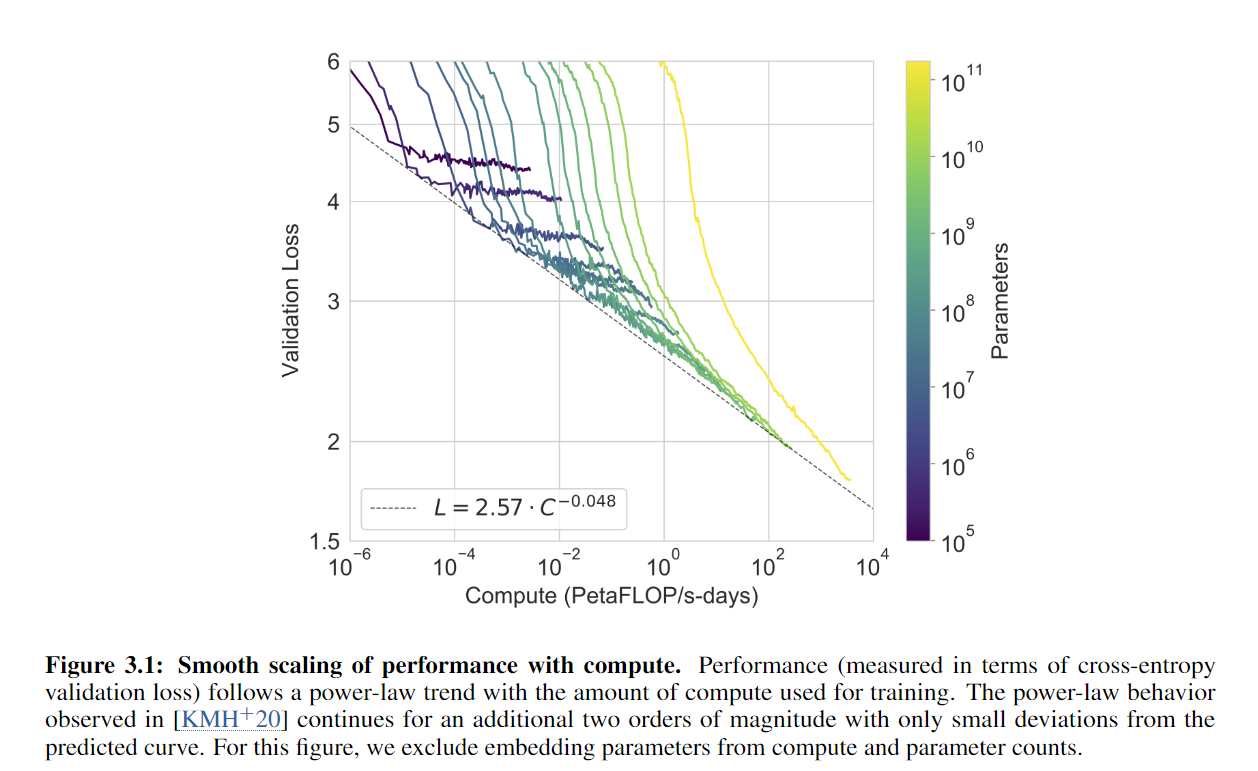
这张图展现的是不同大小模型的计算量上的区别,y轴是验证损失。每个模型最好的点拉成一条线是服从power law的分布,随着训练,损失是线性地往下降的。
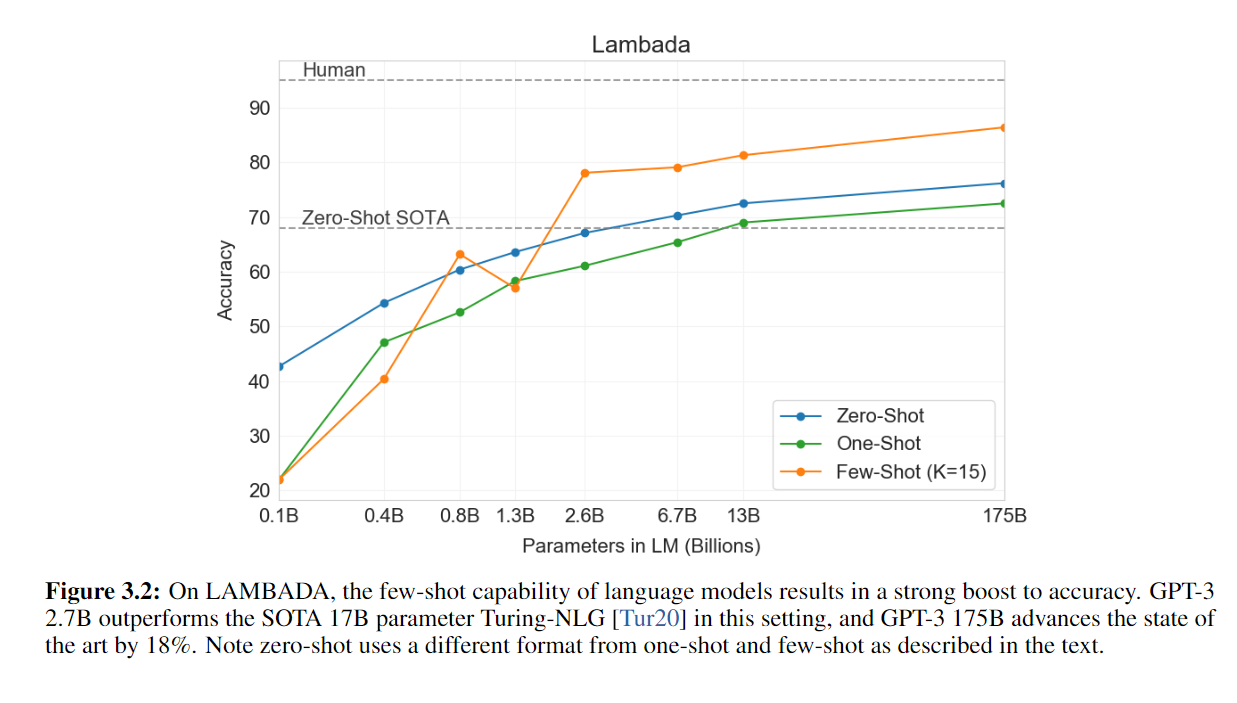
在LAMBADA任务上,和最好的Zero-shot和人类的表现进行了比较。

机器翻译的结果。别的语言翻译到英语(实线)比英语翻译到别的语言(虚线)性能要好。
5. 局限性 Limitations
虽然比GPT-2的效果好很多,但是在文本生成上效果是不太好的。假设需要生成一个很长的文章,如小说,可能会循环使用同样的文字进行生成,很难得到一个剧情类的内容向前推进。
有一些结构和算法上的局限性,因为GPT-3用的是语言类的模型,是往前看的,不能像BERT一样前后看。每次预测使用的是前面的所有的词,但是都有相同的权重,不一定能注意到重点的词。
由于只用了文本,没有使用视频或其他方面的素材,不够通用。样本的有效性不够。有一个不确定性是对于每个样本是从头开始学习还是从模型中找到了之前的任务,然后把它记住。
训练起来非常的贵。
GPT-3和很多别的深度学习的模型一样,是无法解释的。
6. 可能的影响 Broader Impacts
GPT-3这个模型已经很强大了,可以直接部署到生产环境里了。
6.1. 可能会被用来做坏事 Misuse of Language Models
- 散播不实信息,生成一些垃圾邮件,钓鱼邮件,论文造假。生成新闻都有些以假乱真了。
- 公平性、偏见。(男性/女性的偏见)(种族、宗教等等)
- 能耗。训练GPT-3需要几百台机器训练很多天。
8. 结论 Conclusion
我们做了一个175B参数的语言模型,在许多的NLP任务上做了zero-shot, one-shot, few-shot的学习,在很多情况下可以媲美使用更多带标号数据的基于微调的算法。一个卖点是能生成很多高质量的成本,展示了一个不用基于微调的可能性。
读后评论
沐神:
GPT系列在一开始选择了Transformer的二选一里的解码器,可能走了更难的路,但是作者继续进行尝试改进,得到了更好的结果。展示了语言模型能暴力出奇迹的。
我:
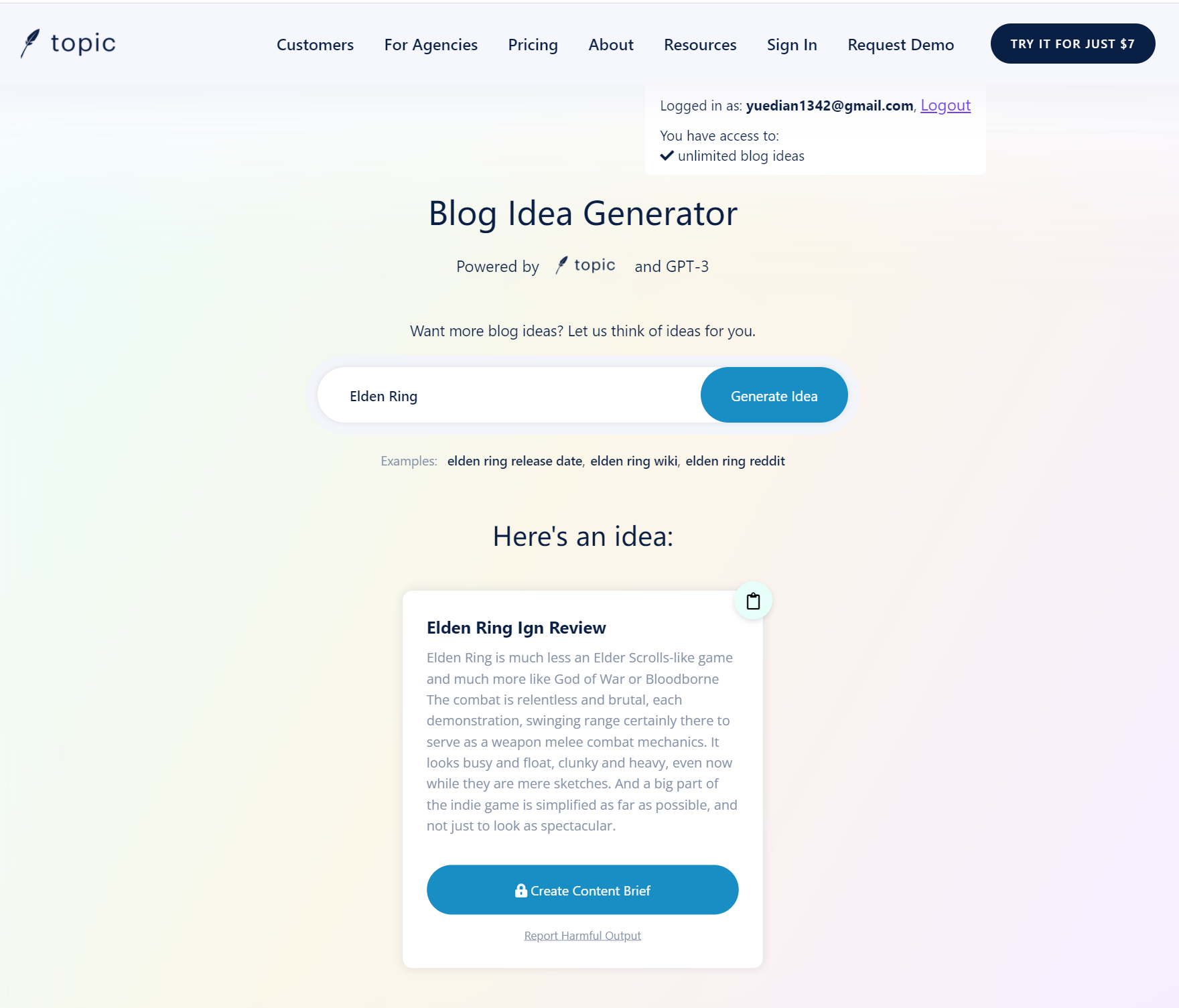
让我试试这些GPT-3 demo!!找到一个可用的,Blog Idea Generator。感觉像是高级版的废话生成器哈哈哈。GitHub Copilot需要体验权限,如果有了我再试试看,看起来的效果也太猛了。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!
如果觉得文章内容不错,还请大力支持哦~
