Transformer 论文笔记
Transformer 论文笔记
论文主要信息
- 标题:Attention Is All You Need
- 作者:Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin
- 机构:Google Brain, Google Research
- 来源:NIPS2017
- 代码:https://github.com/tensorflow/tensor2tensor
摘要 Abstract
序列转录模型主要依赖于复杂的循环或者是卷积神经网络,卷积神经网络一般会使用一个encoder和decoder。在性能最好的模型中,通常也会在编码器和解码器之间使用一个叫注意力机制的东西。
这篇文章提出了一个新的简单的架构,Transformer。这个模型仅仅依赖于注意力机制,没有使用循环或者是卷积。做了两个机器翻译的实验,显示这个模型在性能上很好。并行度更好,并且用更少的时间来训练。在WMT 2014 英语到德语的任务上拿到了28.4 BLEU,比最好的结果高了两个BLEU。在WMT 2014 英语到法语上,做了一个单模型,比所有模型效果都要好,拿到了41.8 BLEU,只在8个GPU上训练了3.5天。Transformer可以泛化到别的任务上效果也特别好。
7. 结论 Conclusion
介绍了Transformer这个模型,是第一个做序列转录的模型,仅仅使用注意力,将所有的循环层换成了multi-headed self-attention。
在机器翻译这个任务上,Transformer能训练得比其他架构快很多,并且能得到更好的结果。作者对这种纯注意力的机制感到非常的激动,想用在别的任务上面。可以用在文本之外的数据,包括图片、语音、视频,使得生成不那么时序化,也是一个研究方向。
这篇文章所有代码放在了tensor2tensor的库中。
1. 导言 Introduction
在时序模型中,当前最常用的是RNN(2017),包括LSTM,GRU。在这里面有两个比较主流的模型,一个是语言模型,一个是在输出结构化信息比较多的时候,会使用一个编码器和解码器的架构。
RNN的特点(同时也是缺点)是给定一个序列的时候,它的计算是这个序列从左往右一步一步做,假设是一个句子的话,就是从左往右一个一个看,对第$t$个词会计算一个值$h_t$,是它的隐藏状态。这个$h_t$是由前面一个词$h_{t-1}$和当前第$t$个词本身决定的。就可以把前面学到的信息通过$h_{t-1}$传到当下,然后和当前的词计算得到输出。
这是RNN处理时序信息的关键,问题也来自于这里。第一是它的计算是一步一步计算的过程,难以并行。第二是历史信息是一步一步向后传递的,如果时序很长的话,那么较靠前的一些信息在后面可能会被丢掉。过去尝试了一些分解提高并行度等等的改进方法,但是本质还是没有很好的解决掉这个问题。
在这篇文章之前,Attention已经成功在RNN的编码器和解码器中有了应用。它主要用在怎样把编码器的东西很有效地传递到解码器。
这篇文章提出的Transformer提出了一个新的模型,不在基于之前的循环神经层,而是纯基于注意力机制了。这个东西是可以并行的,所以能在更短的时间内达到更好的效果。
2. 相关工作 Background
有工作是如何使用卷积神经网络替换掉循环神经网络,减少时序的计算。这些工作主要的问题是:卷积神经网络对于比较长的序列比较难建模。如果两个像素隔得很远的话,得通过很多层卷积才能把它们联合在一起。如果使用Transformer里的注意力机制的话,每一次可以看到所有的像素,每一层就能看到整个序列。卷积比较好的一点是可以做多个输出通道,一个输出通道可以认为是它去识别不一样的模式,作者也想要这样多输出的效果,所以作者提出了一个叫做Multi-Headed Attention,可以模拟卷积神经网络多输出的效果。
自注意力机制,是Transformer比较重要的一个东西,但是在之前也有相关工作已经提出来了。
Memory Networks也是之前的一个研究重点。
在作者的best knowledge里面,Transformer是第一个只依赖自注意力机制来做encoder到decoder之间的工作的模型。
3. 模型架构 Model Architecture
序列模型中现在比较好的一个模型是encoder-decoder的架构。编码器会将一个输入用$(x_1, …, x_n)$表示,比如一个句子,$x_t$用来表示第$t$个词。这个编码器的输出是一个$z = (z_1, …, z_n)$,里面的$z_t$就是对应$x_t$这个词的一个向量的表示。原始的输入变成了机器学习可以理解的一个向量。对于解码器,解码器会拿到编码器的输出$z$,然后生成一个长为$m$的序列($m, n$可能是不一样长的)$(y_1, …, y_n)$,对解码器来说,和编码器最大的区别是这个词是一个一个生成的。在编码器的时候,编码器能一次性看到整个句子,但是在解码的时候,只能一个一个生成,这个是叫做自回归(auto-regresive)的一个模型,因为在这个模型中输出也是输入,比如在生成$y_t$的时候,其实已经可以拿到$(y_1, …, y_{t-1})$作为输入。
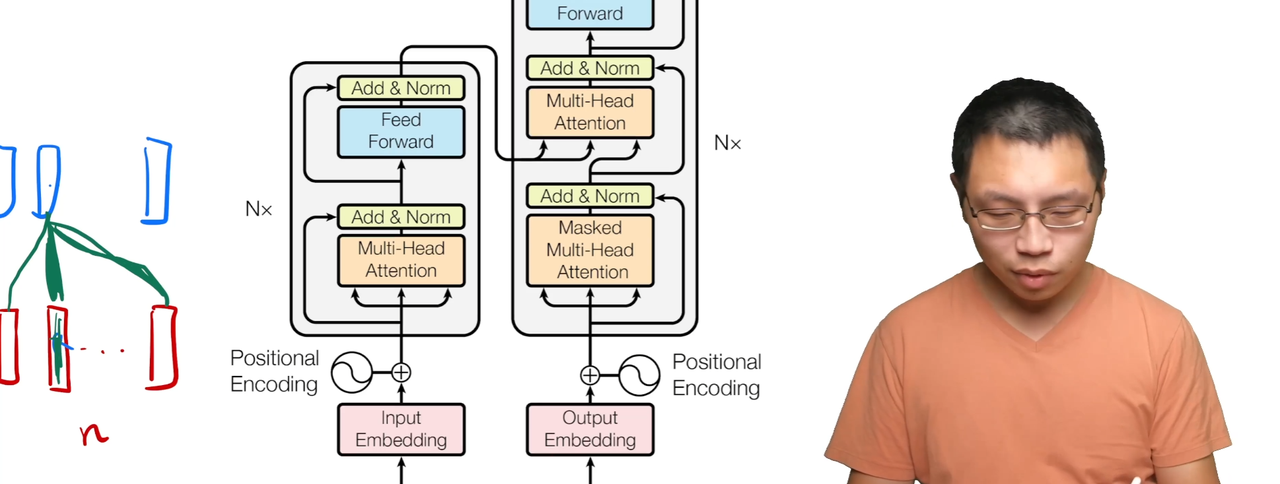
Transformer也是使用了一个encoder-decoder的架构,使用了self-attention和point-wise, fully connected layers连在了一起。下面的Fig 1.展示这个架构:
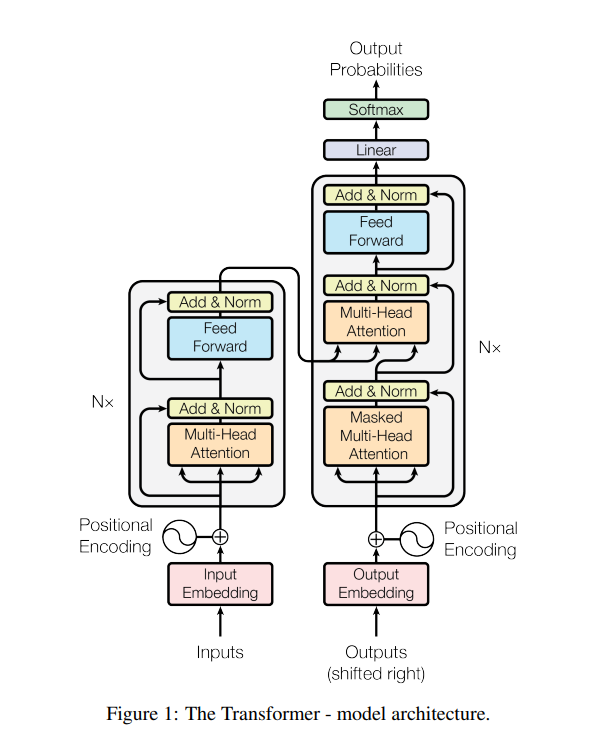
左边是编码器,右边是解码器。
编码器的输入是表述句子的向量,加上了Positional Encoding。进去之后会变成$n$个Transformer的块堆在一起的一个结构,有一个Multi-Head后的前馈神经网络,从输入到Add & Norm有一个残差的连接。可以看成一个MLP(多层感知机)。然后输出接入到解码器的中间。
解码器的输入是之前的输出,一个一个向右移的(shifted right)。输出连接上编码器的输出后继续做一个前馈神经网络,最后输出后做一个softmax得到输出。
3.1. Encoder and Decoder Stacks
介绍具体的Encoder和Decoder是怎么设计的。
Encoder有一个$n = 6$层。每一层有两个子层。第一个子层是multi-head self-attention,第二个子层是用的一个简单的”MLP”。对于每个子层使用了残差连接。然后使用了layer normalization。输出的公式可以写成$LayerNorm(x+Sublayer(x))$,因为残差连接需要输入和输出大小一样,为了简单起见,让每个层输出的维度都是$d_{model} = 512$,固定长度。
什么是Layer Norm,和Batch Norm做对比。
Batch Norm,对每个特征做normalization,在训练的时候把每个小批量的地方算出一个方差均值。在预测的时候会把全局的一个均值算出来,整个数据扫一遍之后把平均的数值存起来,batch norm的时候使用。batch norm还会学习到一个$\lambda _1 \beta$的值,把向量通过学习放成方差和均值为任意一个值的东西。
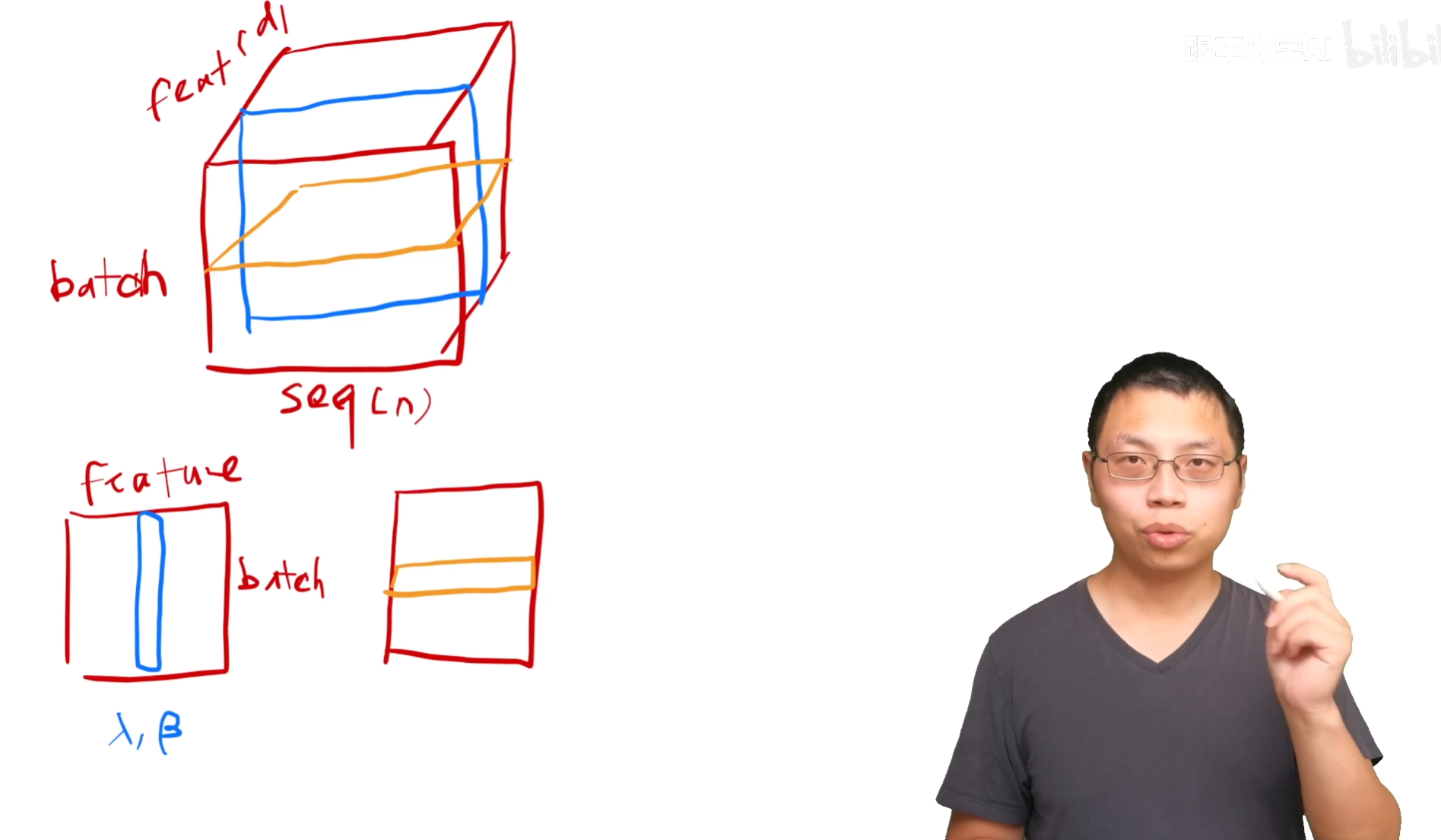
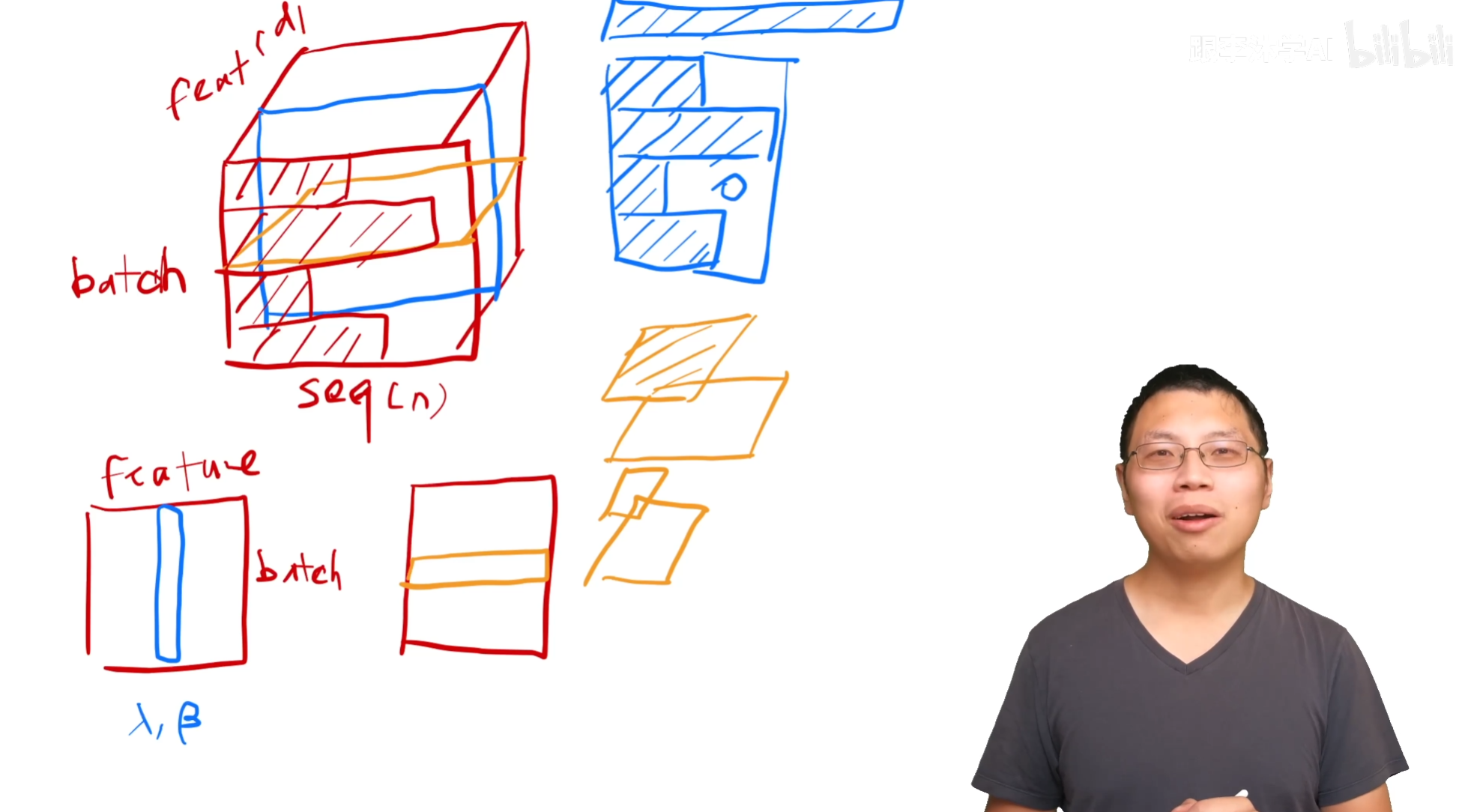
Layer Norm,对每一个样本做normalization,每一行变成均值为0,方差为1。这样让方差的抖动变小,因为对于不同长度的预测样本切出来计算的均值方差更加稳定,相比Batch Norm。
Decoder和Encoder很像,也是由$n=6$层一样的层组成的,有两个子层的内容是和Encoder里一样的。不一样的是有一个第三部分的子层,同样是一个多头的注意力机制,同样使用了残差连接和Layer Norm。在解码的时候使用了自回归,当前的输入是上面的输出。由于在注意力机制的时候能看到全部的输入信息,为了防止在$t$时间的时候看到了$t$时间之后的内容,所以使用了一个带掩码的多头注意力机制。
3.2. Attention
注意力函数是将一个query和一些key-value对映射成输出的函数,这些query, key, value, output都是向量。输出的计算是一个value的加权和。这个权重是从这个value对应的key和query的相似度计算出来的。这个相似度(或者compatibility function)在不同的注意力机制有不同的算法。

3.2.1. Scaled Dot-Product Attention
这一节介绍了Transformer中使用的注意力机制。query和key的长度维度都是$d_k$,value的长度是$d_v$。具体的计算是key和query做内积,做相似度。内积的值越大,相似度越大。
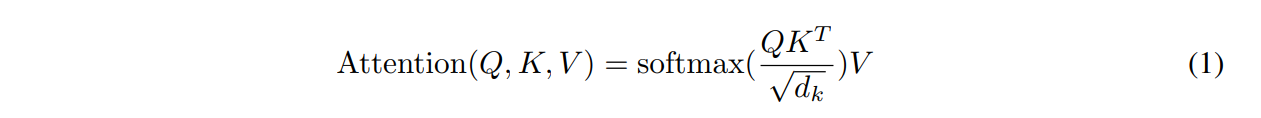
实际中如果每次query都做这个计算会很慢,所以使用Q作为一个query的矩阵,K是key-value的keys矩阵。softmax是对每一行做softmax,行与行之间是独立的,就可以得到每个query对应的权重。权重乘上V这个value的矩阵就得到了需要的输出。

因为是矩阵乘法的形式,所以很好做并行,能很快地进行计算。
有两种比较常见的注意力机制,第一种叫加型的注意力机制,可以处理query和key不等长的情况,另一种叫做点积的注意力机制,也就是作者使用的注意力机制不除以$\sqrt {d_k}$。作者说这两种注意力机制差不多,他这里选择了点乘,因为实现起来比较简单,而且非常高效,两次矩阵乘法就能算好。当$d_k$比较大的时候,点积产生的相对差距会更大,softmax后权重就会更加极端,这样算梯度的时候梯度会比较小,跑不动。所以Transformer中对应$d_k = 512$,除以$\sqrt {d_k}$的效果是比较好的。
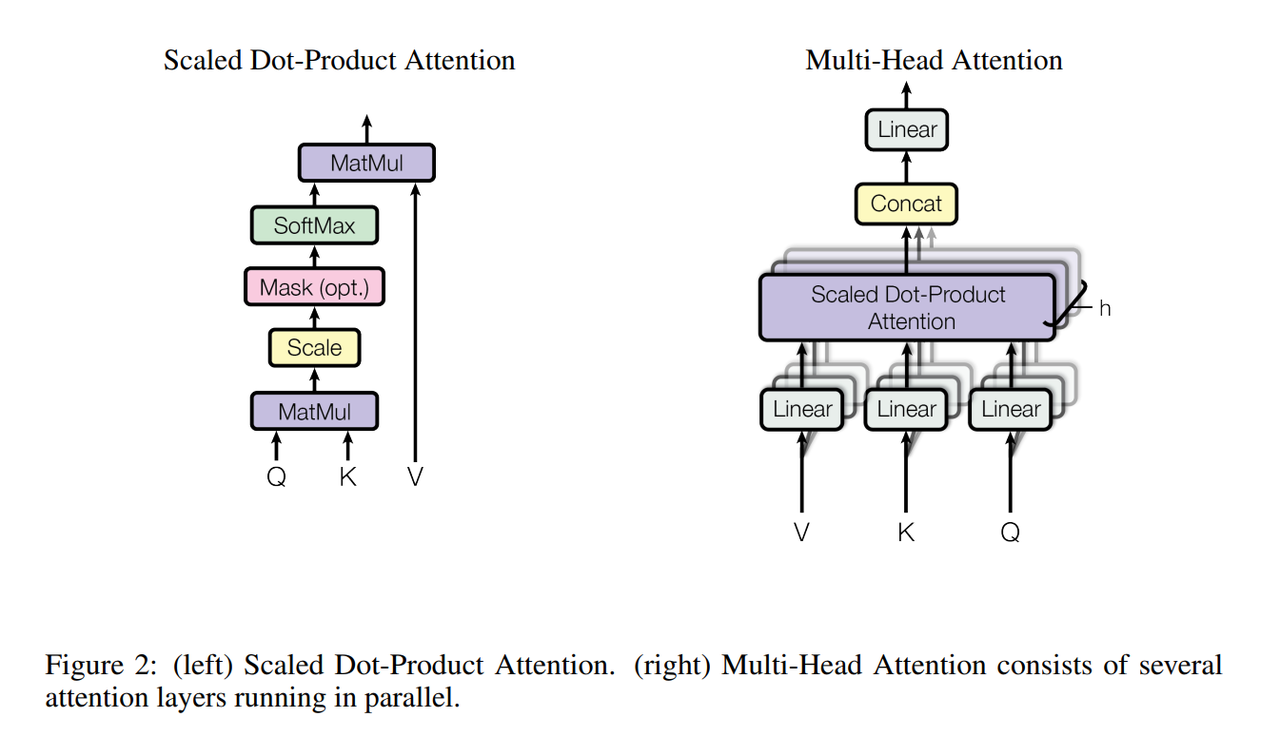
这个矩阵乘法的过程是Fig. 2中左半部分展示的。Mask是为了避免前面时间节点的输出看到靠后时间节点的信息,因为注意力机制实际上会看到全部的信息,Mask可以看成把时间$t$后的数据都变成一个非常大的负数,这样经过了softmax的时候就会非常接近0。这样可以使得做预测的时候和时间信息是一一对应上的。
3.2.2. Multi-Head Attention
Fig. 2的右半部分讲的是Multi-Head Attention具体的设计。作者说与其做一个单独的注意力函数,不如把整个query, key-value投影到低维$h$次,再做$h$次的注意力函数,每一个函数的输出并在一起投影回来,得到最终的输出。通过这样的多头设计,希望这个注意力函数能识别更多不同的模式。

3.2.3. Applications of Attention in our Model
在作者提出的模型中,Fig. 1中黄色的地方表示的是注意力层。 注意力机制有三种使用的情况:
- 每一个Multi-Head Attention的输入是K, V, Q三个矩阵,同样的东西使用了三遍,其实三个都是一个东西,这被叫做自注意力机制。
- 编码器和解码器的第一层都是一样的把相同的输入内容复制成三份进行。解码器不同的是有一个Masked的处理,所以在解码器里后面的内容需要设置为0。
- 第三个注意力层是解码器的第二个子层,Key和Value是来自于编码器的输出,Query是来自于解码器的上一层。相当于通过注意力机制在编码器生成出来的可能结果中挑选最感兴趣的一个作为下一个输出的结果。
3.3. Position-wise Feed-Forward Networks
蓝色的子层,其实是一个MLP(多层感知机)。其实是把MLP对每一个词作用一个,对每个词作用的是同一个MLP,所以对于不同位置的词会有不同的信息,所以叫Position-wise。
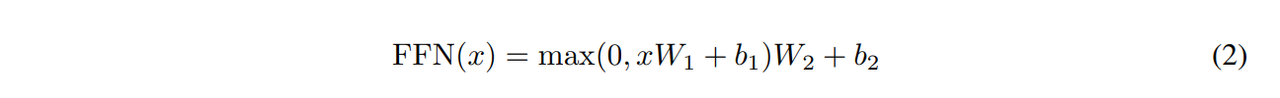
这里的$x$其实就是输出的向量,$d_{model} = 512$,$W_1$对$x$进行一个投影操作后把它变成$d_{ff}=2048$,维度扩大了四倍。进行残差连接后投影回去维度回到512。相当于单隐藏层的MLP。
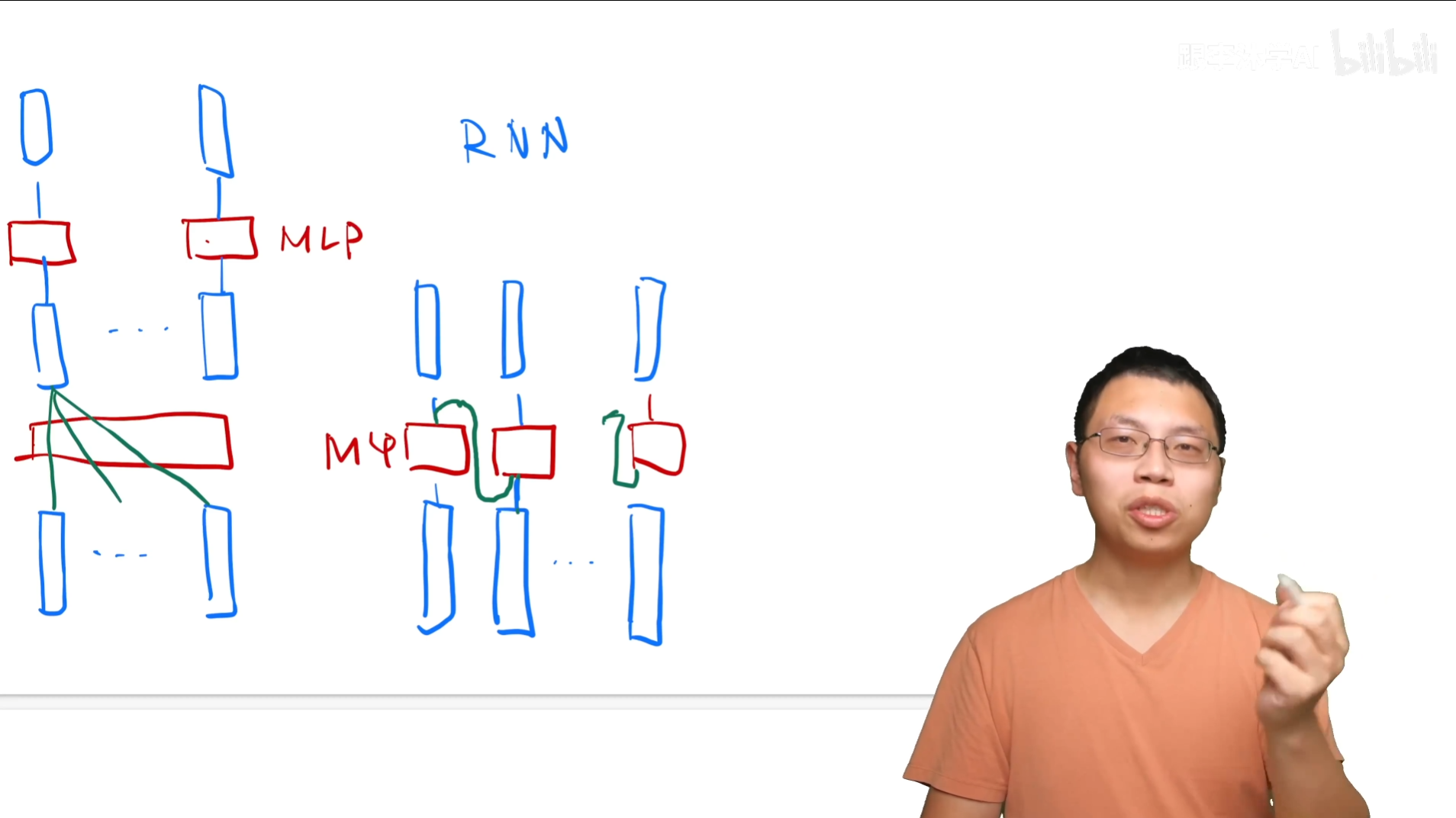
这是Transformer和RNN对于MLP的使用不同的一个对比。重点在于RNN是通过将上一层的MLP信息输入到下一层去获取序列信息的。
3.4. Embeddings and Softmax
需要把词对应成一个长度为$d$的向量进行表示,在Embedding层里,乘以了一个$\sqrt {d_{model}}$,防止加上Positional Encoding后因为scale不同被影响太多。
3.5. Positional Encoding
Attention这个东西是不会有序列信息的,只会通过key-value和query进行计算。给出一句话后词的顺序信息会丢失。Transformer在输入里加入时序信息。
4. 为什么选择自注意力机制 Why Self-Attention
为什么要使用自注意力机制。相对使用循环层和卷积层来说,自注意力具有什么样的优点。

比较了四种层,第一种是自注意力,第二种是循环层,第三种是卷积层,第四种是受限制的自注意力层。比较的三点是每层的计算复杂度(越小越好),每次序列操作要等待的复杂度(越小并行性越好),第三个是信息从一个数据点到另一个数据点要走多远(越小越好)。
5. 实验 Training
5.1. Training Data and Batching
使用了英语-德语的一个37000个token的字典,在两种语言的Embedding的信息是共享的。
5.2. Hardware and Schedule
使用了8块P100的显卡进行训练。Base模型使用小的参数,每一个batch用0.4s,在8张卡上用12小时训练了100000步,能得到不错的性能。在一个大的参数里,每一个batch用1.0s,大模型花了3.5天训练了300000步。
5.3. Optimizer
使用了Adam。学习率几乎不用调。
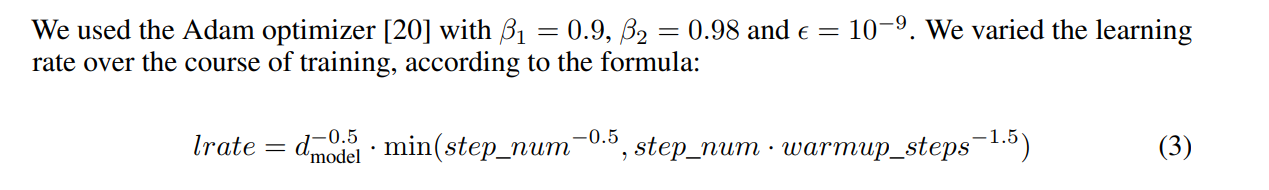
5.4. Regularization
使用的正则化有:
- Residual Dropout。对每一个子层,包括多头注意力层和MLP,在输入上,在进入残差连接之前,进行了一个dropout,$P_{drop}=0.1$
- Label Smoothing。在用softmax学东西的时候,正确的是逼近1,错误的是逼近0。但是其实softmax里很难逼近1,所以训练比较难。所以把正确的词的阈值的置信度是0.1就行了。这里会损失perplexity,可能会损失模型的确信度。但是置信度不那么高会提升精度和BLEU的分数。
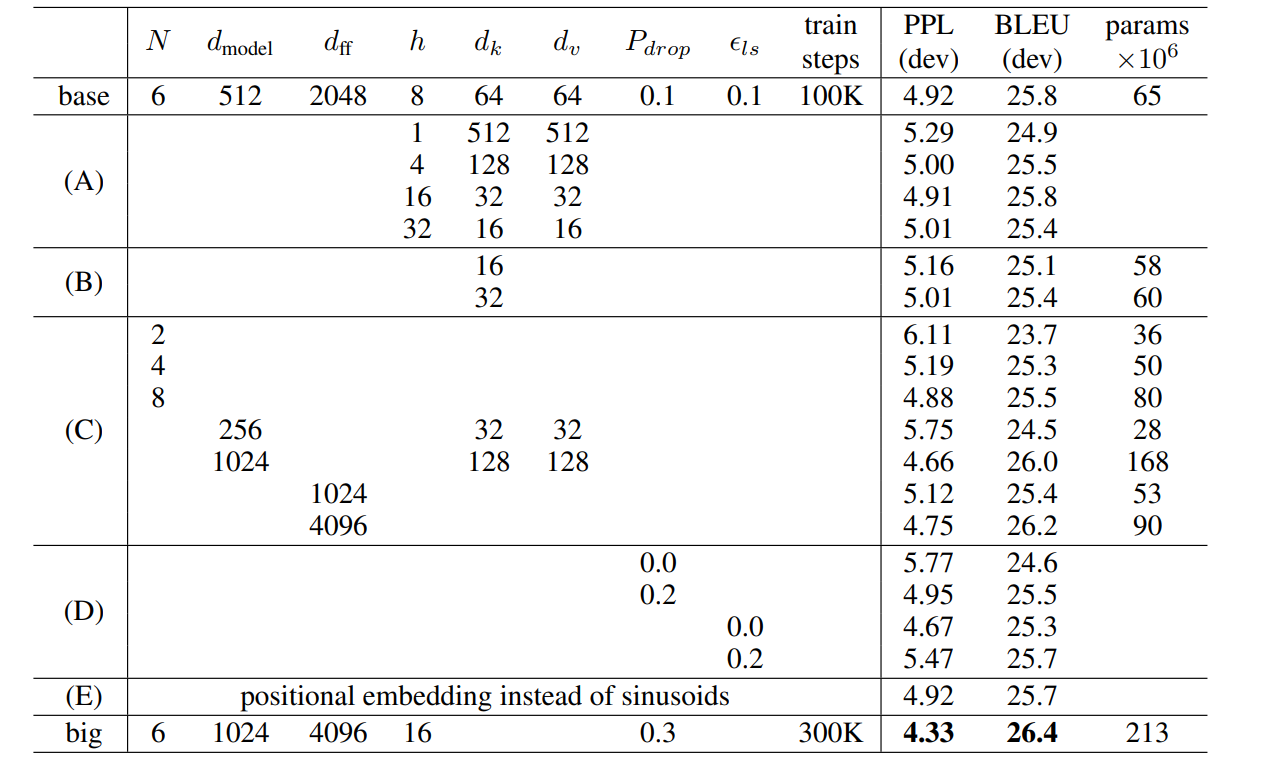
使用的一些超参数如上表。对比了不同超参数下的一些实验结果。
读后评论
沐神:
- 写作是非常简洁的。不太推荐这么写,没有那么多故事让读者有一个很好的代入感,但是这篇文章有发现很多的东西,所以可能没有篇幅这么写。建议写文章的时候有更多的为什么做这个东西,更能说服读者的一些自己的思考。
- Transformer这个模型本身。这个模型可以让大家训练很多很大易训练的模型。很像计算机视觉中的CNN的地位。不用管那么多如何特征提取,数据预处理的工作。预设的模型也让大家的工作比较简单。而且Transformer不仅仅在NLP方向上取得了成绩,在很多领域都能使用,影响力是很大的。能极大减少机器学习对不同领域产生影响的时间。
- 并不只是需要Attention就行了,只是将序列化的信息统一在一起集合起来了,起到了很关键的作用。但是如果没有后续的MLP等等,也是没有Transformer的。
- 为什么能打败RNN呢?现在大家觉得他使用了一个更广泛的归纳偏置。Attention没有做空间上的任何假设,也能得到和RNN差不多的效果。但是可能对数据的抓取效果变差了,所以可能需要更大的模型才有同样的训练效果。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!
如果觉得文章内容不错,还请大力支持哦~
