Analyzing Multi-Head Self-Attention 论文笔记
Analyzing Multi-Head Self-Attention 论文笔记
论文主要信息
- 标题:Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned
- 作者:Elena Voita, David Talbot, Fedor Moiseev, Rico Sennrich, Ivan Titov
- 机构:Yandex, Russia; University of Amsterdam, Netherlands
- 来源:ACL 2019
- 代码:https://github.com/lena-voita/the-story-of-heads
摘要 Abstract
这篇工作对Transformer中的多头注意力机制进行研究。通过剪枝等实验分析评估了单个注意头对模型整体性能的贡献。实验发现最重要、最有用的头通常都扮演着语言上可解释的角色。
当使用基于随机门和$L_0$的可微分松弛的方法进行剪枝的时候,观察到这种特殊的头通常都是最后被剪枝掉的。作者提出的新剪枝的方法可以去除多头注意力机制中绝大部分的头,而不严重影响性能。例如,在英语-俄语的WMT数据集上,编码器中48个头在剪去38个头之后,性能仅下降了0.15的BLEU。
8 结论 Conclusion
作者评估了每个单独的注意头对Transformer模型的翻译任务性能的贡献。作者使用层与层之间关联传播来表明了不同的头的相对贡献是不同的,只有一小部分的头看起来是对翻译任务重要的。在该模型中,重要的头具有一个或多个可解释的功能,包括注意相邻词和跟踪特定的句法关系。
为了确定剩余的难以解释的头是否对模型的性能至关重要,我们引入了一种新的方法来剪枝注意头。我们观察到,重要的注意是最后被剪掉的,这直接证实了他们的重要性。此外,绝大多数的头,特别是编码器的自注意头,可以在不严重影响性能的情况下被移除。
1 导言 Introduction
最近Transformer很火,对其使用的多头注意力机制对翻译任务的重要性的探究是一项具有挑战性的任务。作者对此尝试去探究以下问题:
- 翻译质量在多大程度上依赖于单个编码器的头?
- 单个编码器头是否扮演一致和可解释的角色?如果是的话,哪些是对翻译质量最重要的?
- 哪种类型的模型注意(编码器自我注意、解码器自我注意或解码器-编码器注意)对注意头的数量最敏感,和在哪些层上最敏感?
- 我们能否在保持翻译质量的同时显著减少注意头的数量?
我们首先使用分层关联传播来确定每个编码器层中最重要的头,对于被认为很重要的头,我们试图描述它们所扮演的角色。我们观察到以下几种角色:位置(头指向相邻的标记)、句法(头指向特定句法依赖关系中的标记)和罕见词(头指向句子中出现频率最低的标记)。
虽然我们不能轻易地将活动头的数量作为惩罚项纳入我们的学习目标(即L0正则化器),但我们可以使用可微分的松弛。我们从融合的完整模型开始,在一个持续学习的场景中修剪注意力头,并确定那些留在模型中的角色。
这些实验证实了分层关联传播的研究结果;特别地,具有明确可识别的位置和句法功能的头被最后修剪,因此被证明它在翻译任务中是最重要的。
贡献
作者列举的几点key findings:
- 只有一小部分头对翻译任务很重要
- 重要的头在模型中有一个或多个专门的和可解释的功能
- 这些功能对应的是对相邻单词和特定句法依赖关系中的标记的注意。
2 Transformer的架构 Transformer Architecture
Transformer是一个编码器-解码器模型,编码器和解码器都使用堆叠的自注意层和全连接层。该编码器由$N$层组成,每层包含两个子层:(a)多头自注意机制,(b)前馈网络。多头注意机制依赖于规模的点积注意,它对一个查询$Q$、一个键$K$和一个值$V$进行操作:
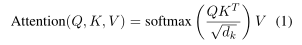
其中$d_k$是Key的维度。在自我注意力中,查询、键和值来自前一层的输出。
多头注意机制获得h个(即每个头一个)不同的$(Q, K, V)$表示,为每个表示计算缩放的点积注意,将结果串接,并通过前馈层投影串接。这可以用与式(1)相同的符号表示:
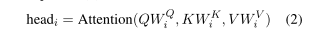
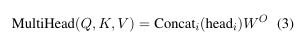
其中$W_i$和$W^O$是参数矩阵。
Transformer网络每一层的第二个组成部分是前馈网络。作者建议使用一个激活ReLU的两层网络。
类似地,解码器的每一层包含上述两个子层以及一个附加的多头注意子层。这个额外的子层接收编码器的输出作为它的键和值。
Transformer以三种不同的方式使用多头注意:编码器自注意、解码器自注意和解码器-编码器注意。在这项工作中,我们主要集中在编码器的自我注意。
4 识别重要的头 Identifying Important Heads
我们将头部的“信心”定义为其最大注意力权重的平均值(不包括句子末尾符号),其中平均值是用于评价的一组句子(开发集)中的符号。一个自信的头通常会将其高度的注意力集中在一个标记上。直觉上,我们可能会认为自信的头对于翻译任务很重要。
分层关联传播(LRP) (Ding et al., 2017)是一种计算网络中某一点神经元对另一点神经元的相对贡献的方法在。这里,我们提出使用LRP来评估每个层的不同头对模型预测的最高logit的贡献程度。结果具有较高相关性值的头可能被认为对模型的预测更重要。
LRP的结果如图1a、2a、2c所示。在每一层中,LRP将少量的头像排列得比其他所有头像都重要。

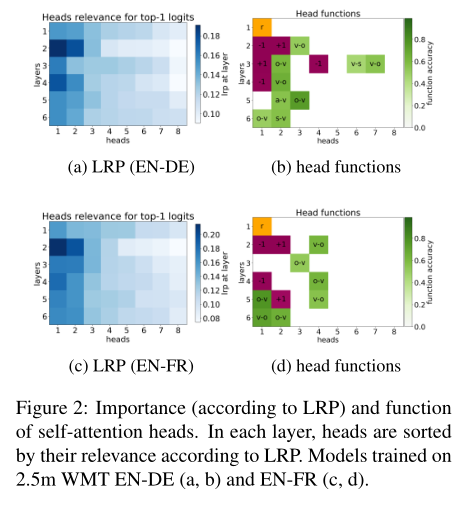
每个头的置信度如图1b所示。我们可以看到,由LRP计算的头像的相关性与其置信度在一个合理的程度上是一致的。这个模式唯一明显的例外是LRP判断为第一层中最重要的头。它是第一层中最相关的头部,但其平均最大关注权重较低。
5 头扮演的是什么角色 Characterizing heads
我们研究了一些特别关注被LRP排名高的头像的注意矩阵,并确定了头像可能发挥的三种功能:
- 位置的作用:头部指向相邻的token
- 句法上的作用:头指向特定句法关系中的符号
- 生僻字:头首指的是句子中出现频率最低的符号
5.1 Positional heads
如果一个头至少90%的时间被分配到一个特定的相对位置(在实验中是-1或+1,即对相邻标记的关注),我们就称其为“位置型”。图1c中英-俄、英-德、英-法的头部分别用紫色表示,并标出相对位置。
可以看出,位置头像在很大程度上对应LRP排名中最自信的头像和最重要的头像。事实上,对于这里考虑的所有语言对,每个位置头的平均最大注意力权重超过0.8。
5.2 Syntactic heads
我们假设,当用于执行翻译时,Transformer的编码器可能负责消除源句子的句法结构的歧义。因此,我们希望知道一个头是否会处理句子中与任何主要句法关系相对应的符号。在我们的分析中,我们观察了以下依赖关系:名义主语(nsubj)、直接宾语(dobj)、形容词修饰语(mod)和副词修饰语(advmod)。这包括一个句子的主要言语论点和一些其他的共同关系。
许多依赖关系经常观察到特定的相对位置(例如,他们常常举行相邻标记,如图3所示)。我们说一头是“语法”如果其准确性是至少高出10%基线看起来最常见的相对位置的依赖关系
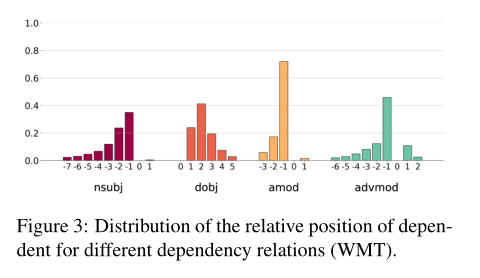
表1显示了英语-俄语在两个领域中所考虑的依赖关系中最精确的标题的准确性。图4比较了在WMT上训练的模型在不同目标语言下的得分。几个头似乎负责相同的依赖关系。这些头在图1c、2b、2d中用绿色表示。
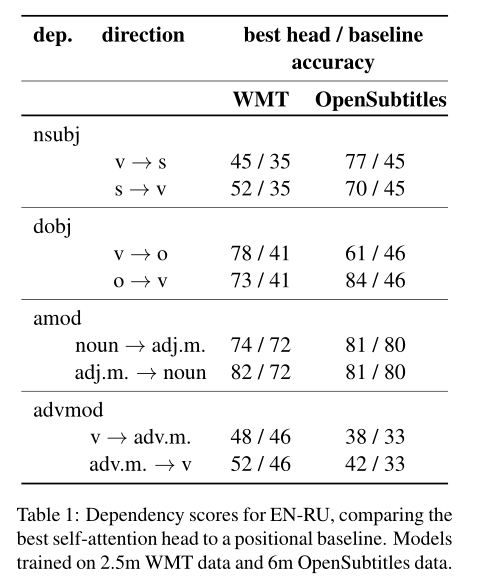
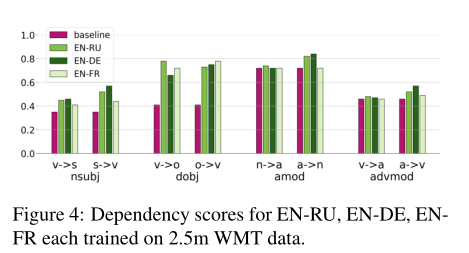
(这个图里展示的是句法头相关的实验内容,但是我不太理解表里的具体含义)
5.3 Rare words
在所有模型(中,我们发现第一层中的一个头被认为比这一层中的任何其他头对模型的预测更重要。
我们发现这个头指向句子中出现频率最低的符号。对于在open字幕上训练的模型,在句子中最不频繁的标记不在最频繁的500个标记中,这个头指向66%的情况下最罕见的标记,以及83%的情况下最不频繁的两个标记之一。对于在WMT上训练的模型,这个头指向了在超过50%的这种情况下最不频繁的两个标记之一。这个头部在图1中以橙色表示。
6 剪枝注意力头 Pruning Attention Heads
我们已经确定了每一层最相关的头的某些功能,并表明它们在很大程度上是可解释的。剩下的头呢?它们对翻译质量来说是多余的,还是扮演着同样重要但不那么容易界定的角色?我们介绍了一种修剪注意力头的方法,试图回答这些问题。我们的方法基于Louizos等人(2018)。当他们修剪个体神经网络权值时,我们修剪整个模型组件(即头部)。我们首先描述我们的方法,然后检查当我们删除头像时,性能如何变化,识别在稀疏模型中保留的头像的功能。
6.1 Method
在每个头前面加入了一个$g_i$,式子3就变成了:
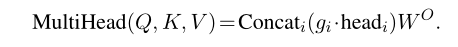
与通常的门不同,gi是特定于头部的参数,独立于输入(即句子)。由于我们希望完全禁用不太重要的头,而不是简单地降低它们的权重,所以理想情况下,我们将对标量gi应用L0正则化。L0范数等于非零组件的数量,会促使模型关闭不太重要的头:
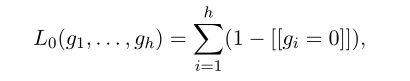
式中,$h$为头数,$[[]]$为指示函数。
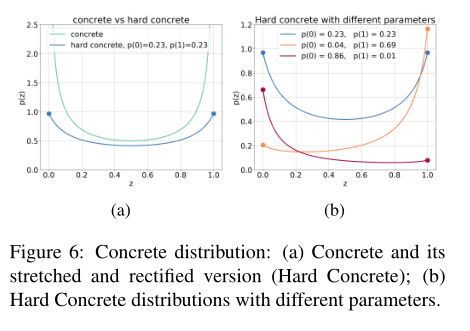
不幸的是,L0范数是不可微的,因此不能直接作为正则项纳入目标函数。相反,我们使用一个随机松弛:每个门的gi现在是一个随机变量独立于特定头像的分布我们使用Hard Concrete分布(Louizos et al., 2018),这是闭区间上混合离散-连续分布的参数化族[0,1],见图6a。分布在0、1、P (gi = 0|φi)、P (gi = 1|φi)处有非零概率质量,其中φi为分布参数。
修改后的优化目标函数为:

6.2 Pruning encoder heads
为了确定哪个头函数在编码器中是最重要的,以及该模型需要多少个头,我们进行了一系列的实验,用门只应用于编码器的自我注意。在这里,我们通过对正则化目标的训练模型进行微调来修剪模型在剪枝过程中,译码器的参数是固定的,只对编码器参数和门限进行微调。通过不对解码器进行微调,我们确保经过修剪的编码器头的功能不会迁移到解码器。
6.2.1 BLEU 量化分数结果
图7提供了BLEU分数。对于更复杂的WMT任务,编码器中的10个头足以保持在全模式的0.15 BLEU范围内。

6.2.2 剩余的头的作用
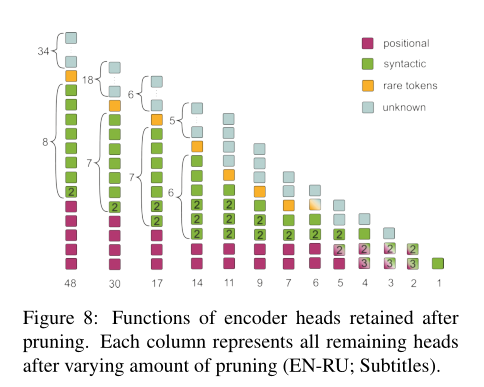
图7的结果表明,即使只有几个头,编码器仍然有效。在本节中,我们研究在剪枝过程中留在编码器中的那些头的功能。图8显示了在修剪模型中,所有头部的功能都用颜色编码。每一列对应一个模型,在修剪后保留特定数量的头。各层的头部按功能排序。有些头可以执行几种功能(例如,s→v和v→o);在本例中显示了函数的数量。
6.3 剪枝编码器以外的head Pruning all types of attention heads
我们发现我们的剪枝技术可以有效地减少编码器中的头的数量,而不会对翻译质量造成重大的下降。现在我们研究修剪模型中所有类型的注意头的效果(不仅仅是在编码器中)。这使我们能够评估不同类型的注意在翻译任务模型中的重要性。在这些实验中,我们对Transformer中的所有多头注意头都添加了门,即编码器和解码器的自注意以及解码器到编码器的注意。
6.3.1 结果
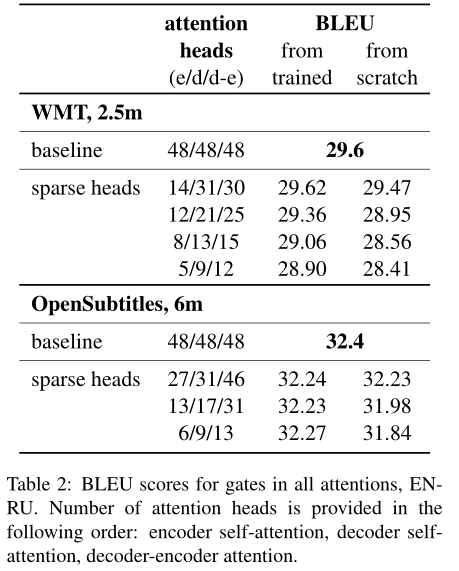
各注意层的剪枝实验结果如表2所示。对京东商城模型训练数据,我们能够修剪几乎3⁄4编码器正面和超过1⁄3的正面在解码器self-attention decoder-encoder注意没有任何明显的翻译质量损失(稀疏,行1)。我们也可以删除模型中超过半数的头和损失不超过0.25BLEU。
6.3.2 Heads Importance
图9显示了在不同修剪速率下,每种注意类型的保留头数。我们可以看到,该模型更倾向于先修剪编码器的自注意头,而解码器-编码器的注意头对于这两个数据集似乎是最重要的。显然,如果没有解码器的注意,翻译就不可能发生。
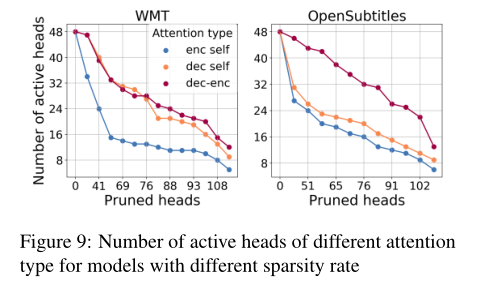
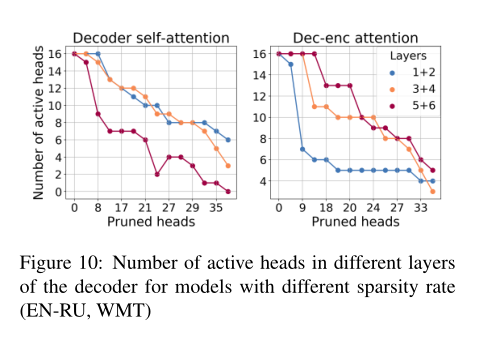
图10显示了对于不同稀疏率的模型,解码器中不同层的主动自注意头和解码器-编码器注意头的数量(为了减少噪声,我们绘制了相邻层中剩余的对注意头的和)。
简短总结 # 你看完这篇论文的总结
这篇文章主要讲了在Transformer的编码器中对自注意头的重要性探索,通过剪枝掉整个头(使用gate让某个头完全不起作用)来比较实验结果。对每个头的重要性进行了评估,并且探究了这些头在翻译任务中为什么重要,他们可能在其中扮演了什么样的角色,在此基础上,作者提出了三种可能很重要的头的类型:
- 注意相邻词的位置的头
- 注意语法、句法关系的头
- 注意生僻字符的头
并且在这个基础上,作者对Transformer的编码器进行了剪枝(删掉头)实验,得到的结果是最终剩下的头普遍也是之前较为重要的头,并且在性能损失较小的情况下通过对重要的头的保留,能够将原来48个头剪去38个。
后来也将这项剪枝头的实验推广到编码器以外的层(解码器等),也进行了实验结果的讨论和比较。
创新点 # 这篇论文自己写的贡献
优劣 # 论文自己写的和你认为的优劣势(相比其他方法)
- 感觉提出每个注意力头可能扮演的角色这一点很新颖。感觉作者用了一个合适的故事来讲他探索自注意力机制的作用。但是代价可能就是这样的工作只足够他在机器翻译这一个任务上进行探究,结果其实不一定有普遍性。
- 作者提出的方法其实是基于前人的一个公式改进,使得L0范数可以微分,他只是在这个基础上直接进行了实验,在剪枝方法上显得比较粗暴,也没有什么新颖。总体上感觉是一篇实验结果和讨论为主的文章。
流程与公式 # 尽量以图为主,附带必要说明
主要实验 # 重点是比较的表格
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!
如果觉得文章内容不错,还请大力支持哦~
