ResNet 论文笔记
ResNet 论文笔记
论文主要信息
- 标题:Deep Residual Learning for Image Recognition
- 简称:ResNet
- 作者:Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun
- 机构:Microsoft Research
- 来源:CVPR 2015
- 代码:https://github.com/pytorch/vision/blob/main/torchvision/models/resnet.py
摘要 Abstract
深的神经网络非常难以训练,于是做了一个残差学习的框架,使得训练非常深的神经网络,比之前轻松了很多。使用residual functions作为层输入去学习,而不是使用之前的unreferenced functions。
论文里提供了非常多的实验的证据,证明残差神经网络非常容易训练,而且能得到很好的训练精度,尤其是在神经网络层数加深之后。
- 在ImageNet上使用了152层深度的ResNet,比VGG网络深8倍,但是计算复杂度更低。
- 在ImageNet测试集上达到了3.57%的错误率,赢下了ImageNet 2015年的竞赛。
- 也演示了在CIFAR-10上训练100和1000层的网络。
对很多视觉的任务来说,深度是非常重要的。仅仅将网络换成之前训练的残差神经网络(深的),在COCO目标检测数据集上得到了28%的相对改进。也通过这个结果赢下了物体检测方面的一系列竞赛。
1. 导言 Introduction
深度卷积神经网络在图像分类上带来了一系列的突破。主要是在深度神经网络中会很自然地(不同层数)得到一些low/mid/high level的特征,用于识别图像。
思考深度对于神经网络效果提升的有效性,可以提出一个问题:一个好的神经网络就是直接把更多的层堆积起来就更好吗?
- 当网络加深的时候,可能会出现gradient vanishing/exploding的问题,对于这个问题可以使用一些方法来解决(比如正则初始化,BN等)。
- 但是另一个问题是,随着网络深度加深,其实性能/精度是变差的。这个不是因为层数变多,模型变大后导致的过拟合(因为训练误差也变大了)。
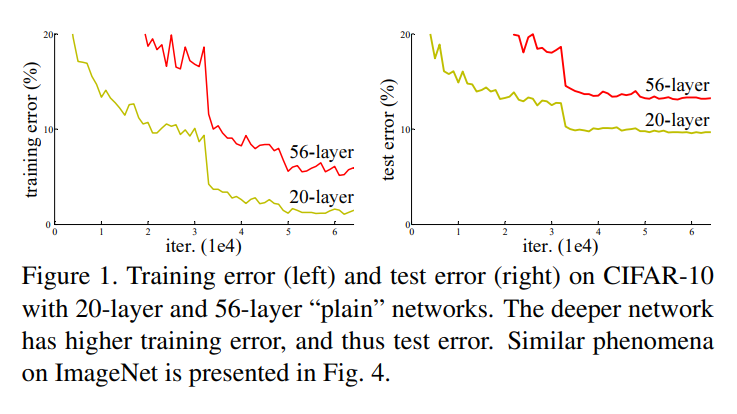
对于第二个问题深入探讨:对于一个结构层数比较浅的神经网络,如果能得到不错的训练效果,那么在上面添加更多的层数,其实理论上应该是能得到更好的表现的,即使是新加的层数相比之前就是一个identity mapping,也不应该让误差更大。但是实验的结果中可以看到, stochastic gradient descent (SGD) (随机梯度下降)找不到这个更优的解,甚至可能层数加深后表现更差。
接下来作者介绍的是 deep residual learning framework,假设在一个已有的输出结果为$x$的层后添加新的层,假设要学习的目标是$H(x)$,那么就让真实的优化目标不是$H(x)$,而是减去原来输出结果$x$的$F(x):=H(x)-x$,并且在这一层的输出结果中把原来的训练结果加上,输出$F(x)+x$。意思是在这一层的训练内容中,不去重复训练已有的训练结果,而是去训练这个结果和这一层训练目标之间的残差(Residual)($H(x)-x$而不是$H(x)$)
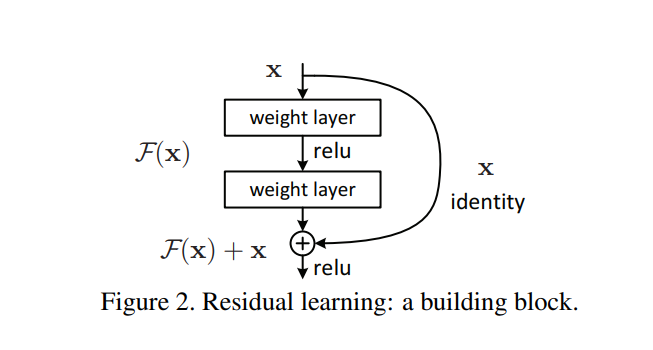
$F(x)+x$这个动作可以在前向神经网络中通过”shortcut connections”实现。这个就是一个identity mapping,而且加的东西没有任何新的参数,只是一个加法,不会有模型计算复杂度上的增加。
通过实验证明了两点:
- 文章提出的residual的网络非常容易优化,但是如果加入”plain”的网络,随着深度加深的同时会得到更高的训练误差。
- residual的网络深度越深,训练的效果就越好
以上的结果在CIFAR-10和ImageNet中都有体现。
2. 相关工作 Related Work
Residual Representation
图像识别中的VLAD是通过字典的残差向量进行编码。还有Fisher Vector是VLAD的一个概率上的表示。
Low-level vision和计算机图形学中求解 Partial Differential Equations (PDEs) 偏微分方程有一个广泛使用的方法Multigrid method。
(沐神:在机器学习中其实使用更广泛,使用residual训练一些弱的分类器叠加起来成为一个强的分类器。这篇论文可能发布在CVPR上主要回顾的是CV相关的工作。)
Shortcut Connections
“highway networks”等等都是比较复杂的运用方法,但是在ResNet中只是比较简单的累加的运用。
3. Deep Residual Learning
3.1. Residual Learning
基本和导言中提到的内容是一致的,相比直接在$x$的输出结果基础上训练目标为$H(x)$的目标函数,改为先去掉上一层的输出结果,训练$F(x):=H(x)-x$,在训练后再加上原先的$x$,输出$F(x)+x$。
3.2. Identity Mapping by Shortcuts
Fig.2 展示的就是整个网络中的一部分,对应的也就是Eqn.(1)
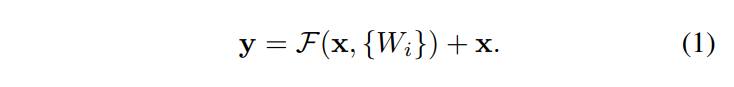
在Eqn.(1)中,要求$ F(x,\lbrace W_i\rbrace ) $和$x$的维度是一样的,这样才能相加,否则就要进行投影或者别的方式,在公式上可以体现为乘了一个新的矩阵$W_s$
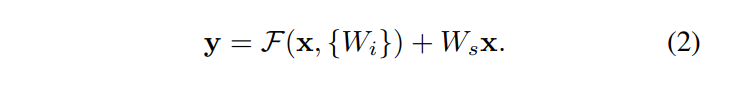
3.3. Network Architectures
残差连接如何处理输入和输出的维度是不等的情况。
两个方案:
- 在输入和输出上添加一些额外的0,使得输入输出的维度相同。
- 在1x1的卷积上进行投影,增加输出通道数。(步幅为2)
3.4. Implementation
ImageNet上的实现:
- 在短边上随机采样到[256, 480]。好处是在裁剪到224*224的时候随机性会更多一些。
- 在颜色上进行了一定的增强。类似亮度、饱和度。
- 使用了Batch Normalization(BN)。
- 初始权重和[13] K. He, X. Zhang, S. Ren, and J. Sun. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In ICCV, 2015. 这篇文章中一样。
- 随机梯度下降(SGD)的批量大小是256,学习率是0.1,每次错误率比较平的时候除以10。
- 训练了$60 \times 10^4$次iterations,weight decay是0.0001,momentum是0.9。
- 没有使用dropout(因为没有全连接层)。
测试的时候:
- 使用了standard 10-crop testing(随机采样10个图片,进行预测求平均)。
- 测试的时候使用了几个不同的分辨率$\lbrace224, 256, 384, 480, 640 \rbrace$
4. 实验 Experiment
4.1. ImageNet Classification
在ImageNet 2012分类数据集上实现ResNet。这个数据集包含1000个类别。这个模型在1.28 million的训练集上进行训练,验证集为50k。最后在100k的测试图片上得到了top-1和top-5的错误率。
对比的是Plain Networks。18-layers和34-layers的版本。
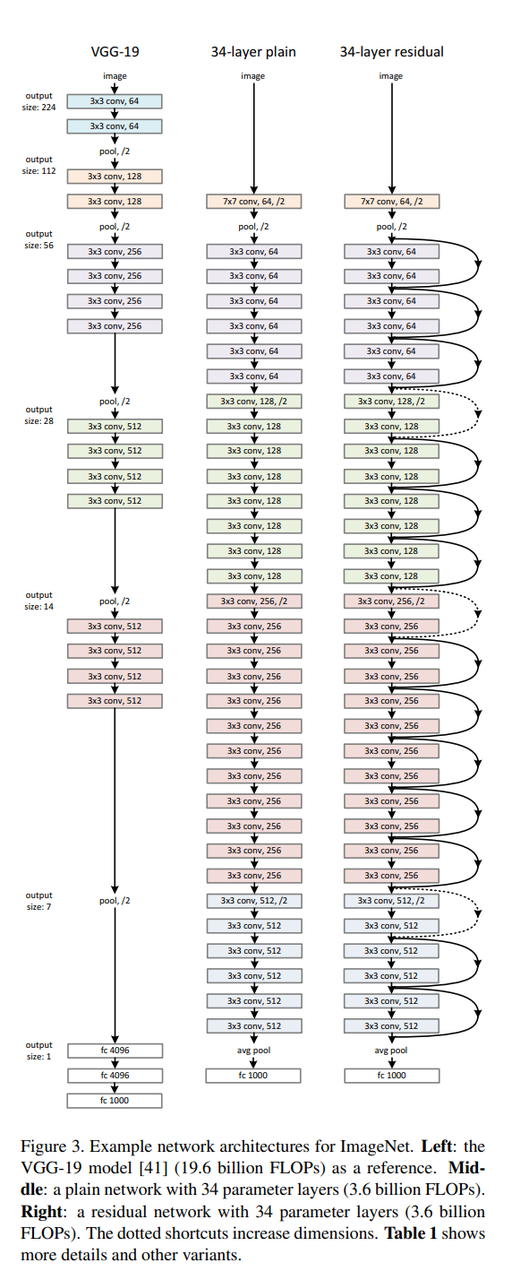
Table 1.是不同深度版本的ResNet的架构:
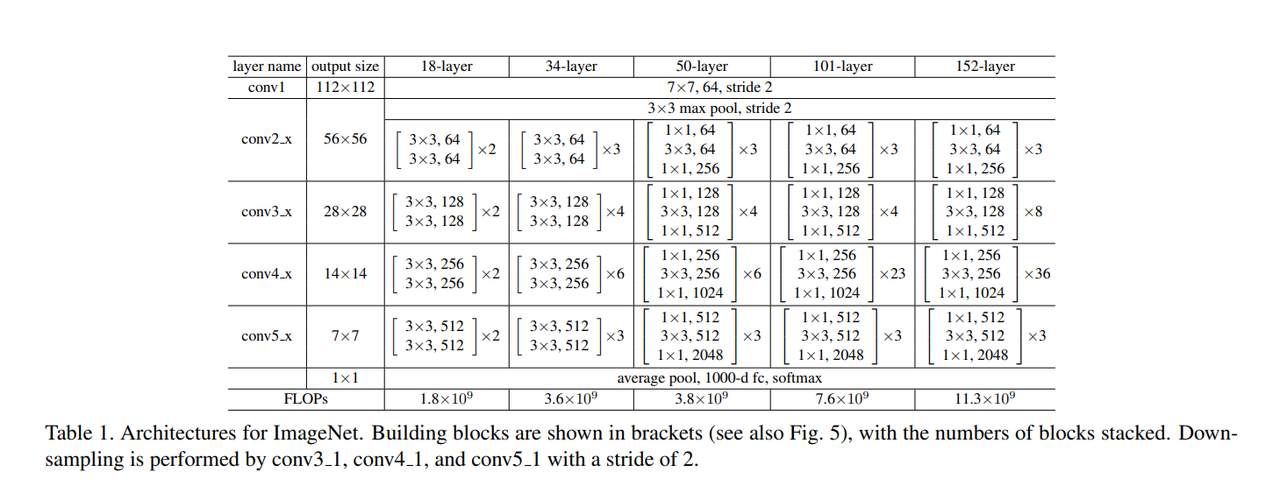
初始的池化层和最后的全连接层的架构是一样的,中间是不一样的。
$\lbrace 64, 128, 256, … \rbrace$表示的是通道的数量。FLOPs,需要进行的浮点计算是可以计算出来的,体现出来深度加深之后其实运算的复杂度没有提高很多。
在Table 2.中对比了Plain Networks在34-layer的时候比18-layer具有更高的训练误差:
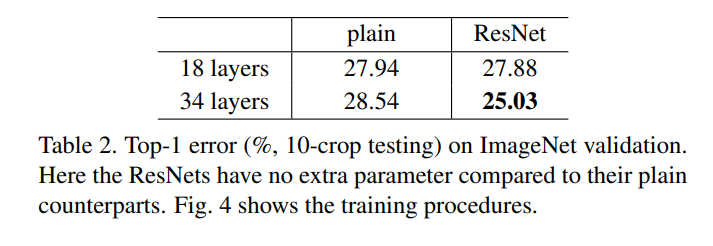
Fig 4.左边是Plain Network,右边是ResNet:
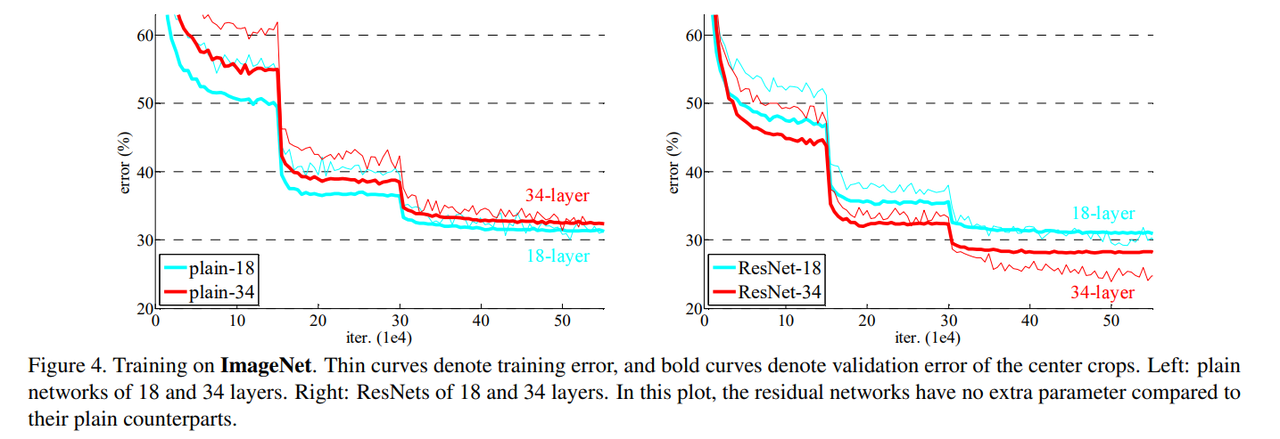
粗线是测试精度,细线是训练精度。下降较明显的是学习率*0.1,改变梯度下降的步子。
主要展现的是有残差连接后:
- 网络深层越深,训练和测试误差越低。
- 训练的时候收敛更快。
在Table 3.中比较了Shortcut Connection的三种方案:
A. 在维度形状不同的时候添加0。
B. 在维度不同的时候使用投影增加输出通道。
C. 不管维度是否相同,都使用投影。
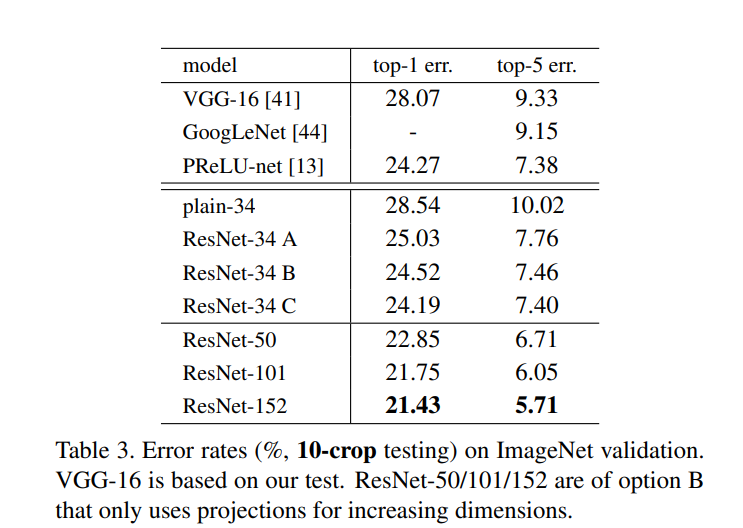
B和C基本对A都有较大的提升。C看起来会更好一点,但是每次都做投影会带来更高的计算复杂度,所以在ResNet实现的时候选择使用了B方案,只在形状改变的时候进行投影(大约只有4次改变)。
Deeper Bottleneck Architectures
如何加深ResNet的深度,引入了一个叫做bottleneck design的东西,如Fig. 5:
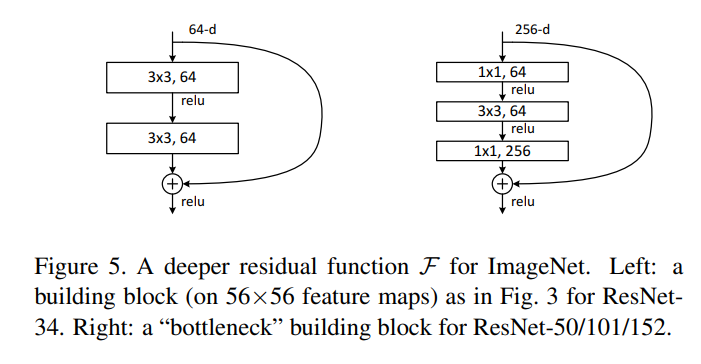
通道数变大,从64-d到了256-d,因为直接计算的话是平方级的复杂度,会多16倍,所以进行投影到了原来的64-d。训练后再投影到256-d,这样计算复杂度会低很多。对应了Table 1.中更深层次的ResNet的设计。
Table 4. 展示随着深度加深,误差越来越小:
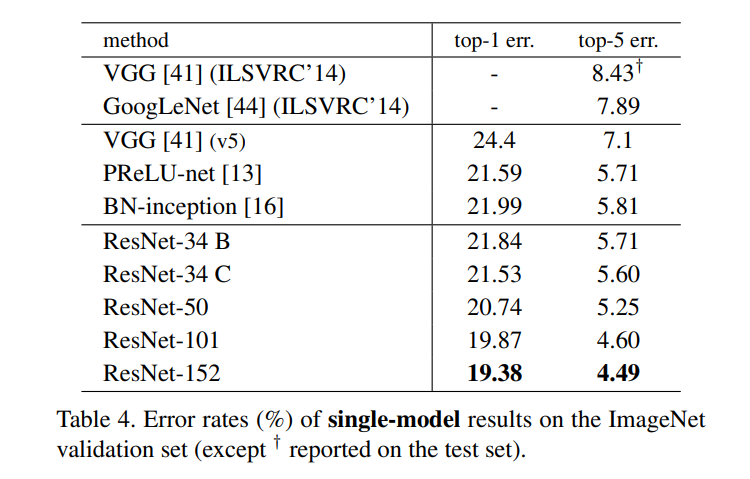
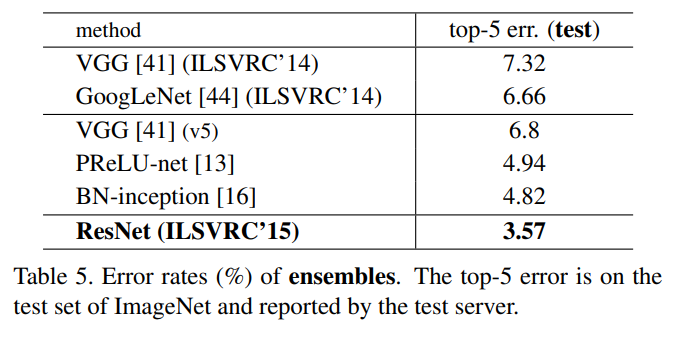
Table 5. 对比的是其他的方法在ImageNet测试集上的表现:
4.2. CIFAR-10 and Analysis
CIFAR-10的数据集上基本是32*32的小图片,比ImageNet小很多,所以在CIFAR-10层上进行了新的设计的ResNet。Table 6.展示了1000层的ResNet误差率会比100层的高一些。
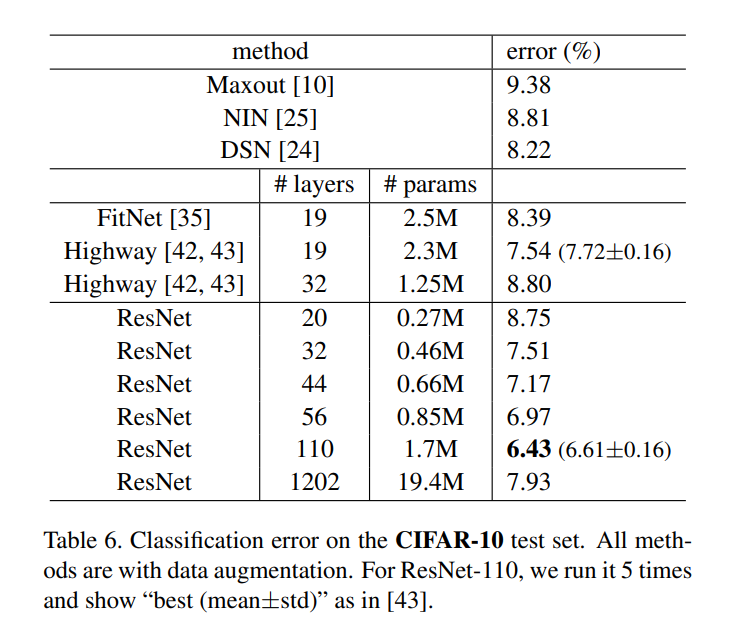
Fig 6. 主要表示的还是加入residual后效果还是比plain的网络要好很多。
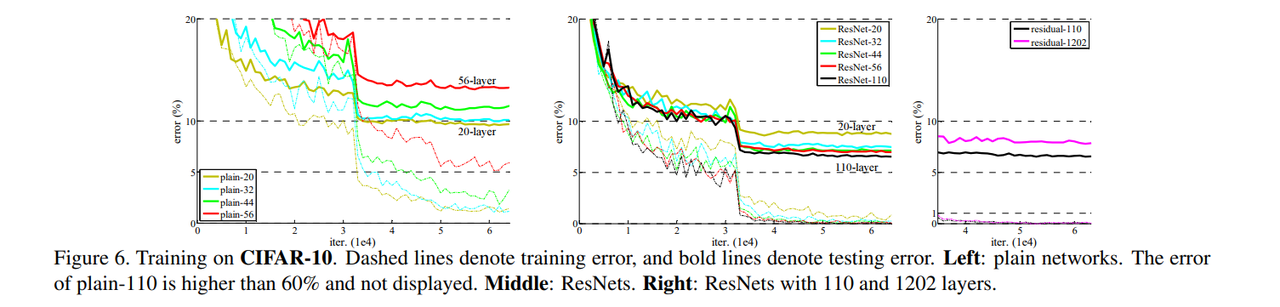
Fig 7. 表示的是随着深度的加深,Standard deviations (std) 标准差的变化。而且可以看到的是,因为有投影的过程,所以可能在改变维度形状的时候标准差也是有波动的,但是如果按照维度大小排序后,整个网络的标准差是收敛的:
可能是因为ResNet学的是残差,在深度加深很多后没有新的东西可以学了,所以1000层的表现没有更好。
4.3. Object Detection on PASCAL and MS COCO
展现了在目标检测上的数据集结果页很好。Detail在Appendix里。
(沐神:这篇文章没有Conclusion,全都是展示实验结果。)
读后笔记
沐神:
在加入更多层次的网络的时候,如果训练精度更差,不如简单直观化,去学习一个更简单的内容。这篇论文没有做太多分析和数学证明,而是讲了很多实验的结果。
ResNet训练起来比较快主要是因为梯度收敛保持的比较好。原先求导的过程中,每一次梯度可能是0附近的高斯分布,乘起来可能就越来越小,出现了gradient vanishing的问题,但是ResNet中相当于加了一项$g(x)$进行求导,避免了梯度消失的问题。

在CIFAR-10上使用1000层的网络,有overfitting,但是没有特别做regularization也能保持在一个比较低的误差。“收敛没有任何意义”,但是ResNet可以一直train下去。ResNet主要是保持了一直有一个比较大的梯度,避免了SGD收敛到了一个比较不准确的位置,能够持续训练下去,所以可以得到一个比较好的结果。
简单的尝试 Pytorch官方 ResNet实例
跑了一下单张图片上使用训练好的ResNet-18的预测情况,之后跑跑在ImageNet和CIFAR-10上训练的实验。
主要关注:
- 代码中关于Residual的和Shortcut Connection的部分的实现。
- 如果不进行手动调Learning Rate,会持续收敛吗?沐神说的不手动调的现代的方法是什么?

本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!
如果觉得文章内容不错,还请大力支持哦~
